Create a read replica cluster
You can create a universe that includes both a primary cluster and a read replica cluster in a hybrid cloud deployment, as well as dynamically add, edit, and remove a read replica cluster. The example presented in this document shows how to deploy a universe with primary cluster in Oregon (US-West) and read replica cluster in Northern Virginia (US-East).
Note
- YSQL read replica support is currently in Beta.
- Yugabyte Platform does not support read replica configuration for Kubernetes and OpenShift cloud providers.
Create the universe
You start by navigating to Dashboard and clicking Create Universe. Use the Primary Cluster > Cloud Configuration page to enter the following values to create a primary cluster on GCP provider:
-
Enter a universe name as helloworld3.
-
Enter the set of regions as Oregon.
-
Set the replication factor to 3.
-
Set instance type to n1-standard-8
-
Add the configuration flag for YB-Master and YB-TServer as
leader_failure_max_missed_heartbeat_periods10. Since the data is globally replicated, remote procedure call (RPC) latencies are higher. You can use this flag to increase the failure detection interval in such a high-RPC latency deployment.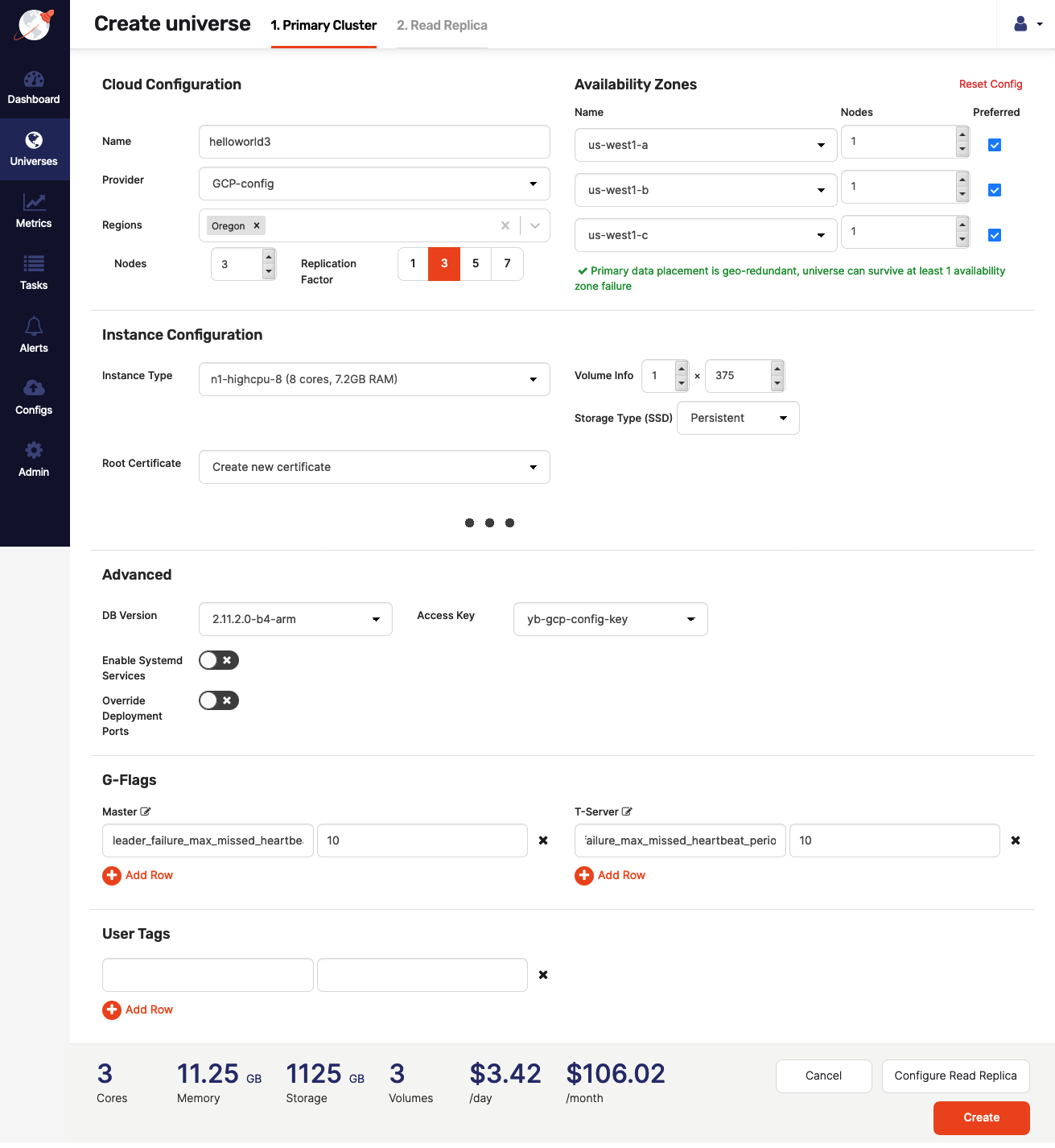
The next step is to click Configure Read Replica and then specify the following on the Read Replica > Cloud Configuration page to create a read replica cluster on AWS:
- Enter the set of regions as US East.
- Set the replication factor to 3.
- Set the instance type to c4.large.
Since you do not need to a establish a quorum for read replica clusters, the replication factor can be either even or odd.
To finish the process, click Create.
Examine the universe
While the universe is being created, Dashboard should look similar to the following illustration:
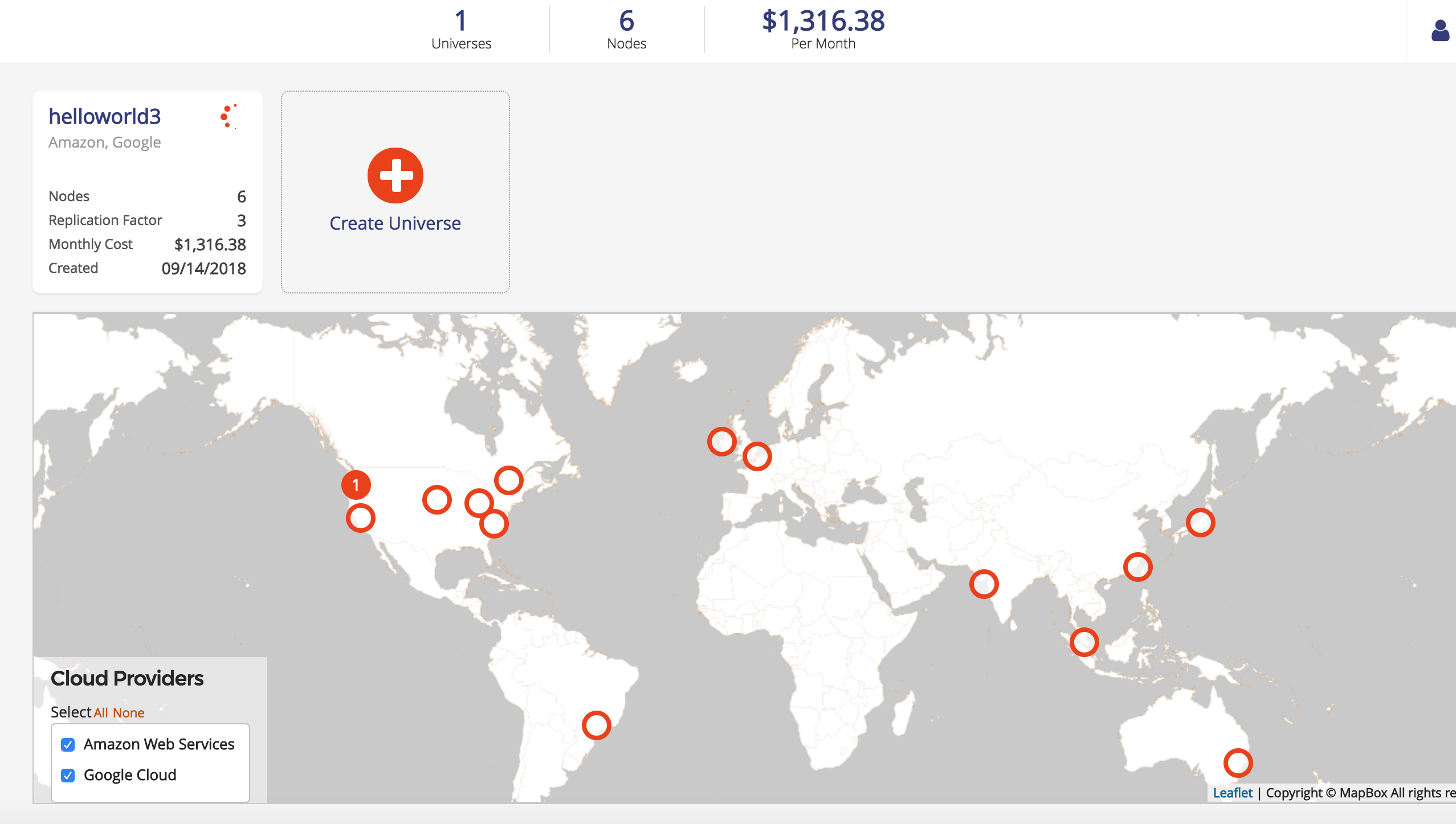
Once the universe has been created, Dashboard displays the primary and read replica cluster information, as well as shows the distinct clusters on the map.
Universe nodes
To see a list of nodes, navigate to Nodes. Notice that the nodes are grouped into primary cluster and read replicas, and read replica nodes have a readonly1 identifier appended to their name.
Navigate to the cloud provider's instances page. In GCP, browse to Compute Engine > VM Instances and search for instances that have helloworld3 in their name. The following illustration shows the result corresponding to your primary cluster:
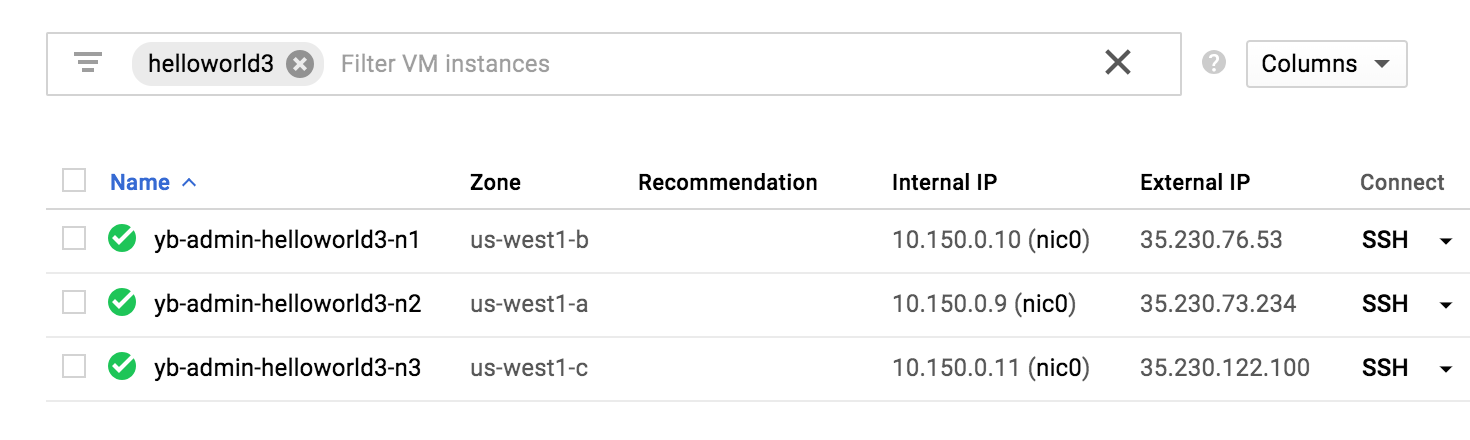
In AWS, navigate to Instances and perform the same search. The following illustration shows the result corresponding to your read replica cluster:

This confirms that you created a hybrid cloud deployment with the primary cluster in GCP and the read replica cluster in AWS.
Add, remove, edit a read replica cluster
Yugabyte Platform allows you to dynamically add, modify, and remove a read replica cluster from an existing universe.
Create a new universe called helloworld4 with a primary cluster identical to helloworld3 but without any read replica cluster. Click Create and wait for the universe to be ready. Once this is done, navigate to Overview and click Actions > Edit Read Replica.
Use the Cloud Configuration page to enter the same information that you entered for the read replica cluster in helloworld3 and click Edit Read Replica.
When done, open Nodes and verify that you have three new read replica nodes, all in AWS. To edit the read replica cluster, once again click Actions > Edit Read Replica. Add a node to the cluster (availability zones are populated automatically) and click Edit Read Replica.
When the universe is ready, open Nodes to find the new read replica node for a total of four new nodes.
To delete the read replica cluster, open the Cloud Configuration page and click Delete this configuration.
Upon completion, navigate back to Nodes and verify that you only see the three primary nodes from the initial universe creation.