Configure the Amazon Web Services (AWS) cloud provider
You can configure Amazon Web Services (AWS) for YugabyteDB using the Yugabyte Platform console. If no cloud providers have been configured yet, the main Dashboard page prompts you to configure at least one cloud provider.
Prerequisites
To run YugabyteDB nodes on AWS, you need to supply your cloud provider credentials on the Yugabyte Platform console. Yugabyte Platform uses the credentials to automatically provision and deprovision YugabyteDB instances. A YugabyteDB instance includes a compute instance, as well as attached local or remote disk storage.
Configure AWS
Configuring Yugabyte Platform to deploy universes in AWS provides several options that you can customize, as per the following illustration:
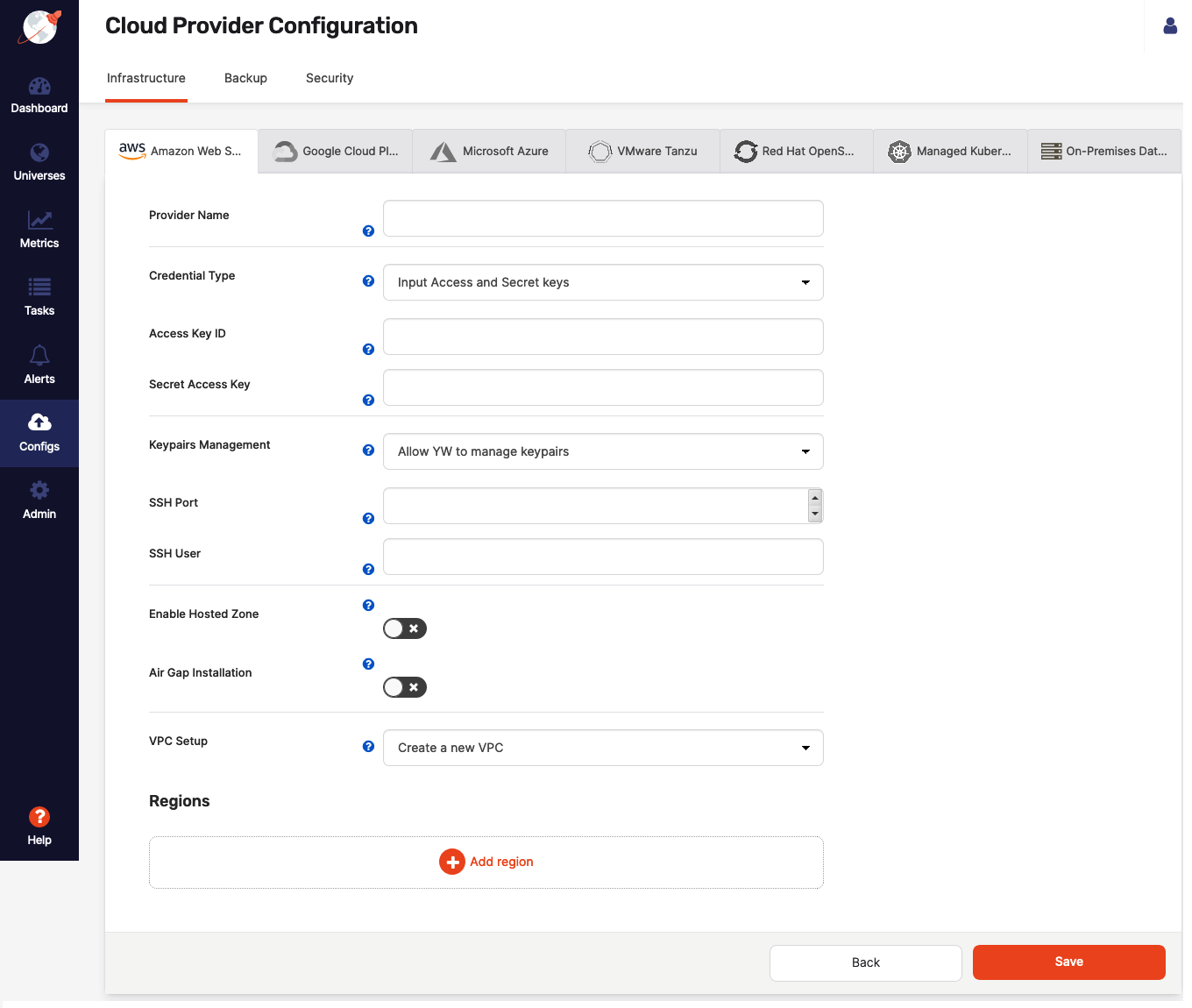
Provider name
Provider name is an internal tag used for organizing your providers, so you know where you want to deploy your YugabyteDB universes.
Credentials
In order to deploy YugabyteDB nodes in your AWS account, Yugabyte Platform requires access to a set of cloud credentials which can be provided in one of the following ways:
- Directly provide your AWS Access Key ID and Secret Key.
- Attach an IAM role to the Yugabyte Platform VM in the EC2 tab. For more information, see Deploy the YugabyteDB universe using an IAM role.
SSH Key Pairs
In order to be able to provision Amazon Elastic Compute Cloud (EC2) instances with YugabyteDB, Yugabyte Platform requires SSH access. The following are two ways to provide SSH access:
- Enable Yugabyte Platform to create and manage Key Pairs. In this mode, Yugabyte Platform creates SSH Key Pairs across all the regions you choose to set up and stores the relevant private key part of these locally in order to SSH into future EC2 instances.
- Use your own existing Key Pairs. To do this, provide the name of the Key Pair, as well as the private key content and the corresponding SSH user. Currently, this information must be the same across all the regions you choose to provision.
If you use Yugabyte Platform to manage SSH Key Pairs for you and you deploy multiple Yugabyte Platform instances across your environment, then the AWS provider name should be unique for each instance of Yugabyte Platform integrating with a given AWS account.
Hosted zones
Integrating with hosted zones can make YugabyteDB universes easily discoverable. Yugabyte Platform can integrate with Amazon Route53 to provide managed Canonical Name (CNAME) entries for your YugabyteDB universes, which will be updated as you change the set of nodes to include all relevant ones for each of your universes.
Global deployment
For deployment, Yugabyte Platform aims to provide you with easy access to the many regions that AWS makes available globally. To that end, Yugabyte Platform allows you to select which regions to which you wish to deploy and supports two different ways of configuring your setup, based on your environment: Yugabyte Platform-managed configuration and self-managed configuration.
Yugabyte Platform-managed configuration
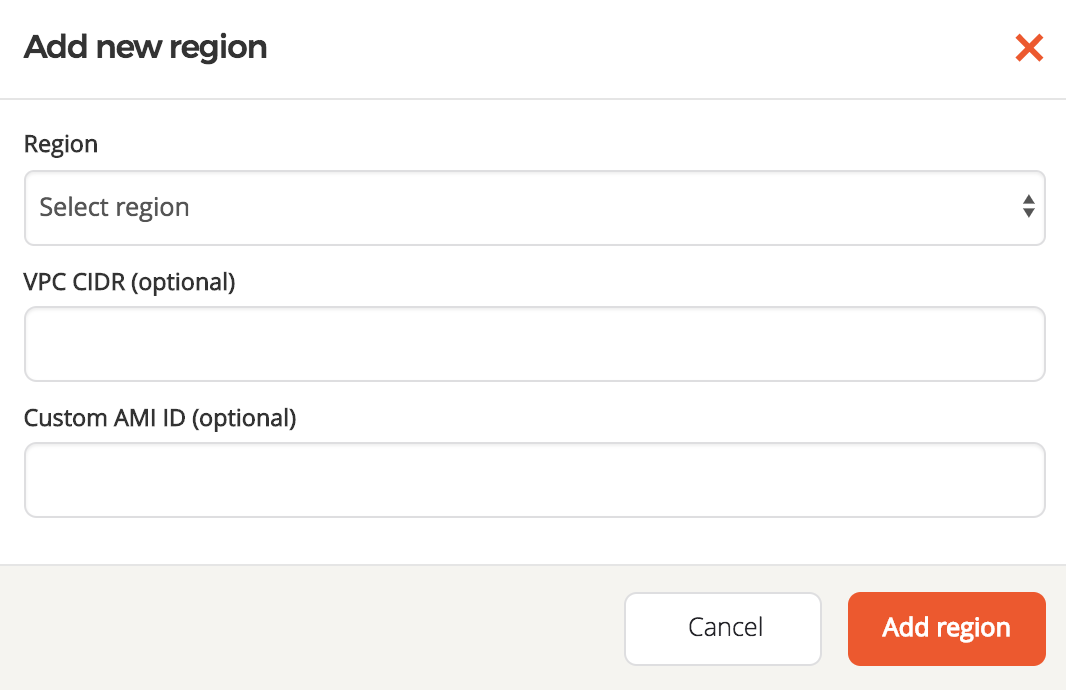
If you choose to use Yugabyte Platform to configure, own, and manage a full cross-region deployment of Virtual Private Cloud (VPC), Yugabyte Platform will generate a YugabyteDB-specific VPC in each selected region, then interconnect them, as well as the VPC in which Yugabyte Platform was deployed, using VPC Peering. This mode also sets up all other relevant subcomponents in all regions, such as Subnets, Security Groups, and Routing Table entries.
You have an option to provide the following:
-
A custom classless inter-domain routing (CIDR) block for each regional VPC. If not provided, Yugabyte Platform will choose defaults, aiming to not overlap across regions.
-
A custom Amazon Machine Image (AMI) ID to use in each region. For a non-exhaustive list of options, see Ubuntu 18 and Oracle 8 support. If you do not provide any values, a recent AWS Marketplace CentOS AMI is used.
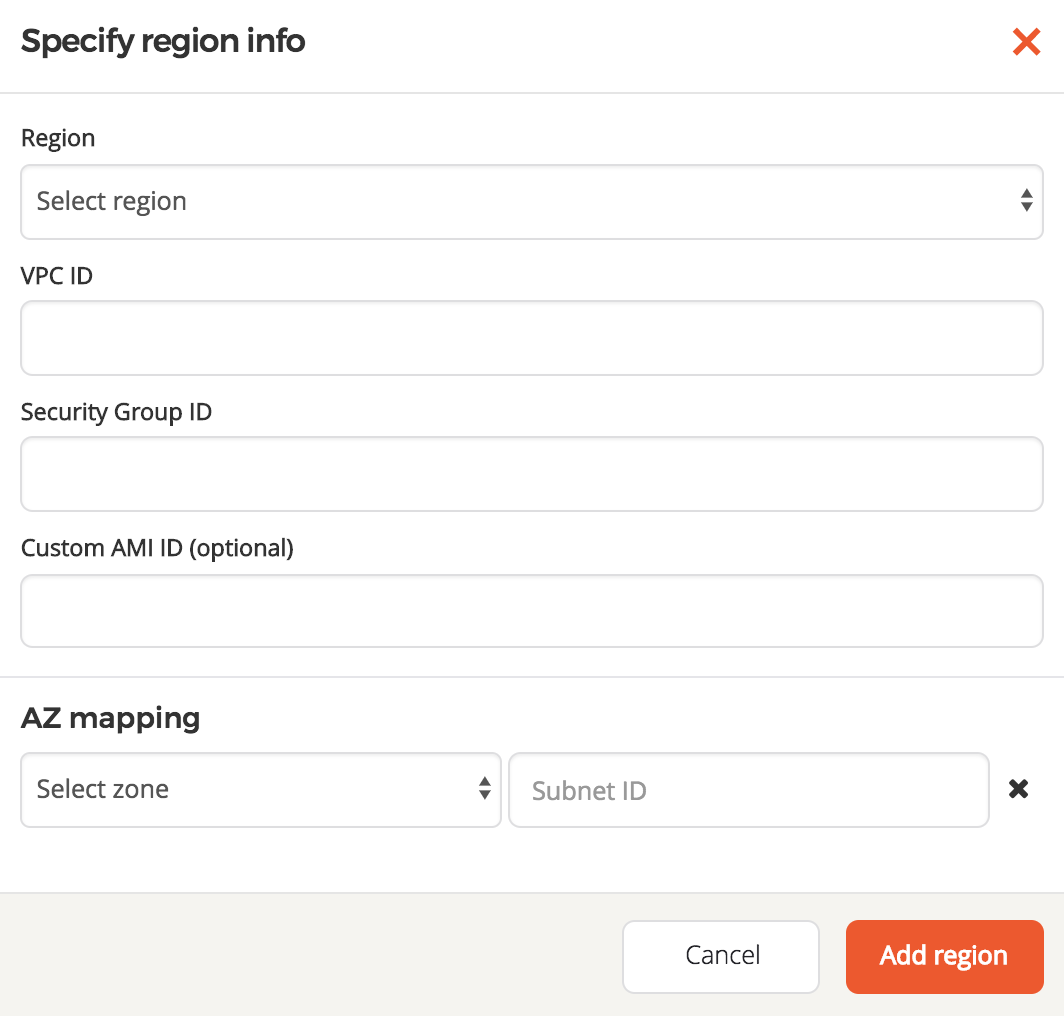
Self-managed configuration
You can use your own custom VPCs. This allows you the highest level of customization for your VPC setup. You can provide the following:
- A VPC ID to use for each region.
- A Security Group ID to use for each region. This is attached to all YugabyteDB nodes and must allow traffic from all other YugabyteDB nodes, even across regions, if you deploy across multiple regions.
- A mapping of what Subnet IDs to use for each Availability Zone in which you wish to be able to deploy. This is required to ensure that Yugabyte Platform can deploy nodes in the correct network isolation that you desire in your environment.
- A custom AMI ID to use in each region. For a non-exhaustive list of options, see Ubuntu 18 and Oracle 8 support. If you do not provide any values, a recent AWS Marketplace CentOS AMI is used.
If you choose to provide your own VPC information, you will be responsible for having preconfigured networking connectivity. For single-region deployments, this might simply be a matter of region or VPC local Security Groups. Across regions, however, the setup can get quite complex. It is recommended that you use the VPC peering feature of Amazon Virtual Private Cloud (Amazon VPC) to set up private IP connectivity between nodes located across regions, as follows:
- VPC peering connections must be established in an N x N matrix, such that every VPC in every region you configure must be peered to every other VPC in every other region.
- Routing table entries in every regional VPC should route traffic to every other VPC CIDR block across the PeeringConnection to that respective VPC. This must match the Subnets that you provided during the configuration step.
- Security groups in each VPC can be hardened by only opening up the relevant ports to the CIDR blocks of the VPCs from which you are expecting traffic.
- If you deploy Yugabyte Platform in a different VPC than the ones in which you intend to deploy YugabyteDB nodes, then its own VPC must also be part of this cross-region VPC mesh, as well as setting up routing table entries in the source VPC (Yugabyte Platform) and allowing one further CIDR block (or public IP) ingress rule on the security groups for the YugabyteDB nodes (to allow traffic from Yugabyte Platform or its VPC).
- When a public IP address is not enabled on a universe, a network address translation (NAT) gateway or device is required. You must configure the NAT gateway before creating the VPC that you add to the Yugabyte Platform console. For more information, see NAT and Tutorial: Creating a VPC with Public and Private Subnets for Your Clusters in the AWS documentation.
Ubuntu 18 and Oracle 8 support
In addition to CentOS, Yugabyte Platform allows you to bring up universes on the following host nodes:
- Ubuntu 18.04, which requires Python 2 or later installed on the host, as well as the provider created with a custom AMI and custom SSH user.
- Oracle 8, which requires the provider created with a custom AMI and custom SSH user, assumes that gtar or gunzip is present on the host AMI, and uses the firewall-cmd client to set default target
ACCEPT. Yugabyte Platform support for Oracle 8 has the following limitations:- Only Red Hat Linux-compatible kernel is supported to allow port changing. There is no support for Unbreakable Enterprise Kernel (UEK).
- Systemd services are not supported.
Marketplace acceptance
If you did not provide your own custom AMI IDs, before you can proceed to creating a universe, verify that you can actually spin up EC2 instances with the default AMIs in Yugabyte Platform. The reference AMIs come from a Marketplace CentOS 7 Product. While logged into your AWS account, navigate to that link and click Continue to Subscribe.
If you are not already subscribed and have not accepted the Terms and Conditions, then you should see the following message:

If so, click Accept Terms and wait for the page to switch to a successful state. Once the operation completes, or if you previously subscribed and accepted the terms, you should see the following:
Now, you are ready to create a YugabyteDB universe on AWS.