Create a standard cluster
Standard clusters support multi-node and highly available deployments and are suitable for production deployments.
Features
Standard clusters include the following features:
- No limit on cluster size - choose any cluster size based on your use case.
- Multi node replication factor (RF) of 3 clusters with availability zone and node level fault tolerance. To deploy multi-region clusters, contact Yugabyte Support.
- Horizontal and vertical scaling - add or remove nodes and vCPUs, and add storage to suit your production loads.
- VPC networking support.
- Automated and on-demand backups.
- Create as many as you need.
- Provisioned with a stable release of YugabyteDB. You can choose to provision with an edge release. Before deploying a production cluster on an edge release, contact Yugabyte Support.
- Available in all regions.
- Enterprise support.
Prerequisites
- You need to create a billing profile and add a payment method before you can create a standard cluster. Refer to Manage your billing profile and payment method.
- If you want to use dedicated VPCs for network isolation and security, you need to create the VPC before you create your cluster. Yugabyte Cloud supports AWC and GCP for peering. Refer to VPC networking.
Create a cluster
To create a cluster, on the Clusters page, click Add Cluster to start the Create Cluster wizard.
The Create Cluster wizard has the following three pages:
Select Cluster Type
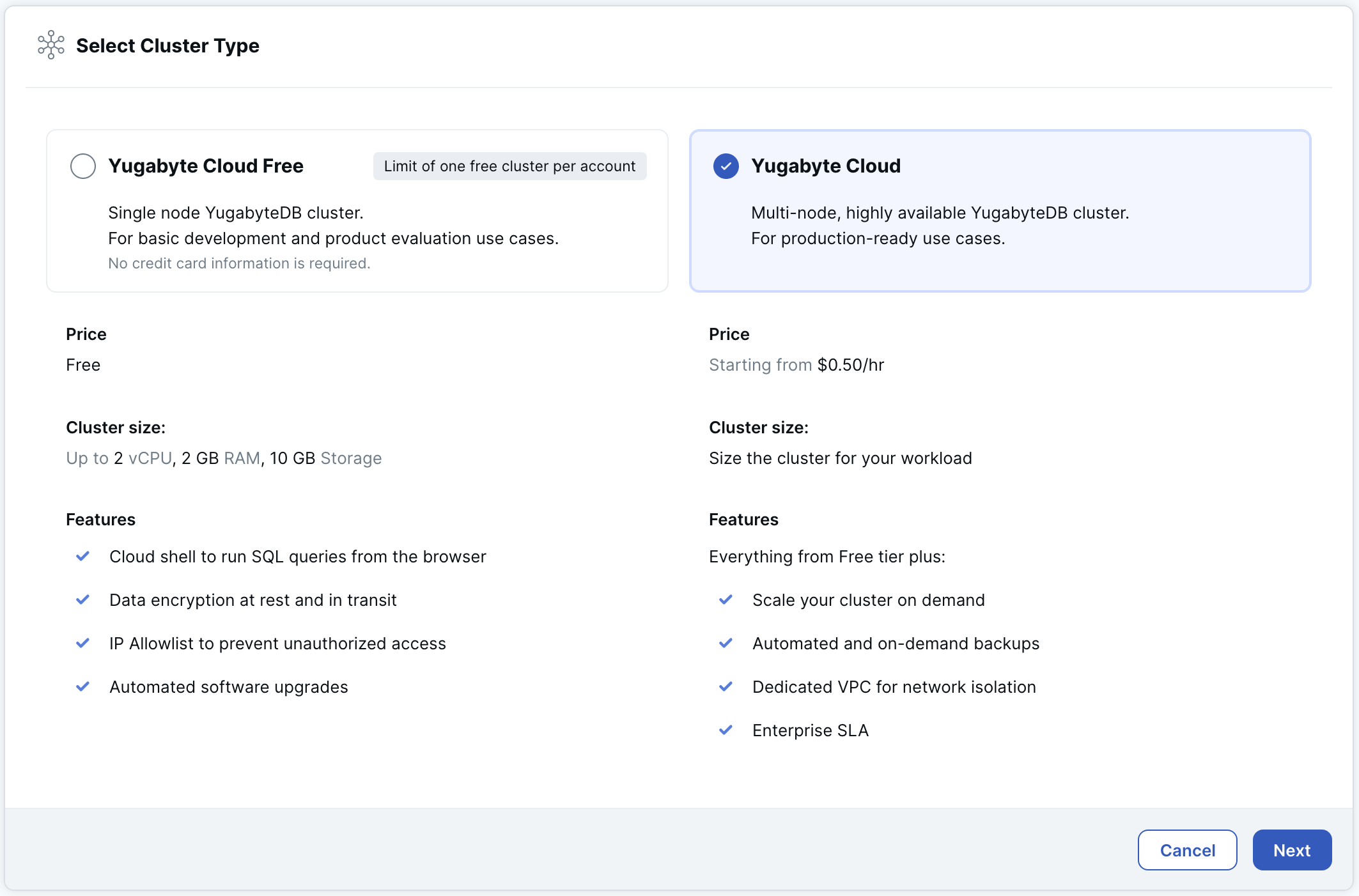
Select Yugabyte Cloud and click Next to display the Cluster Settings page.
Cluster Settings
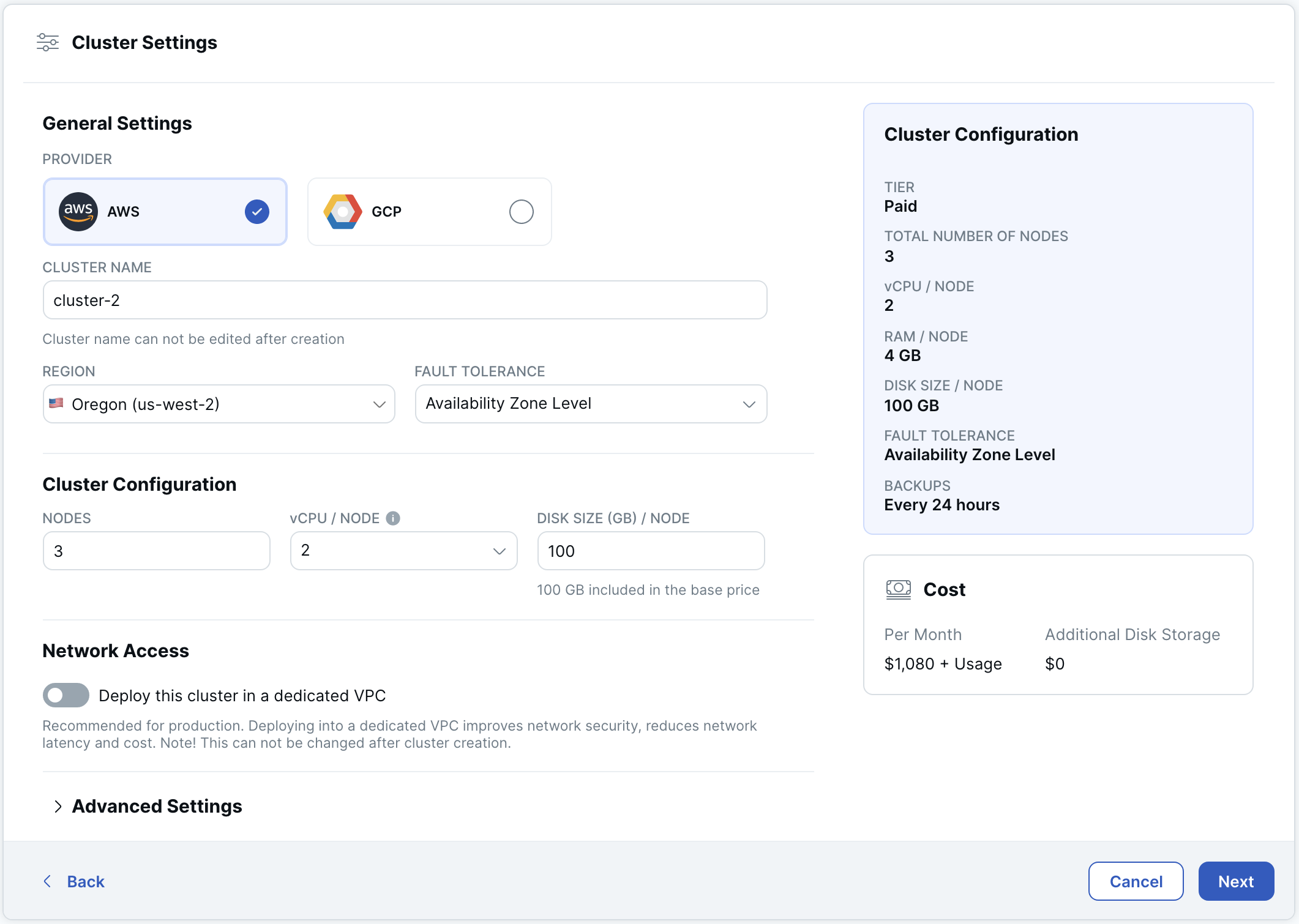
Set the following options:
-
Provider: Choose a cloud provider - AWS or GCP. (For Azure, contact Yugabyte Support.)
-
Cluster Name: Enter a name for the cluster.
-
Region: Choose the region where the cluster will be located.
-
Fault Tolerance determines how resilient the cluster is to node and cloud zone failures:
- None - single node, with no replication or resiliency. Recommended for development and testing only.
- Node Level - a minimum of 3 nodes deployed in a single availability zone with a replication factor (RF) of 3. YugabyteDB can continue to do reads and writes even in case of a node failure, but this configuration is not resilient to cloud availability zone outages. For horizontal scaling, you can scale nodes in increments of 1.
- Availability Zone Level - a minimum of 3 nodes spread across multiple availability zones with a RF of 3. YugabyteDB can continue to do reads and writes even in case of a cloud availability zone failure. This configuration provides the maximum protection for a data center failure. Recommended for production deployments. For horizontal scaling, nodes are scaled in increments of 3.
-
Cluster Configuration determines the size of the cluster:
- Nodes - enter the number of nodes for the cluster. Node and Availability zone level clusters have a minimum of 3 nodes; Availability zone level clusters increment by 3.
- vCPU/Node - enter the number of virtual CPUs per node.
- Disk size/Node - enter the disk size per node in GB.
-
Network Access: If you want to use a VPC for network isolation and security, select Deploy this cluster in a dedicated VPC, then select the VPC. Only VPCs using the selected cloud provider are listed. The VPC must be created before deploying the cluster. Refer to VPC networking.
-
Database Version: By default, clusters are deployed using a stable release. If you want to use an edge release for a standard cluster, click Advanced Settings and choose a release. Before deploying a production cluster using an edge release, contact Yugabyte Support. If you have arranged a custom build with Yugabyte, it will also be listed here.
Cluster costs are estimated automatically under Cost. + Usage refers to any potential overages from exceeding the free allowances for disk storage, backup storage, and data transfer. For information on how clusters are costed, refer to Cluster costs.
Standard clusters support both horizontal and vertical scaling; you can change the cluster configuration after the cluster is created using the Edit Configuration settings. Refer to Configure clusters.
Database Admin Credentials
The admin credentials are required to connect to the YugabyteDB database that is installed on the cluster.
You can use the default credentials generated by Yugabyte Cloud, or add your own.
For security reasons, the admin user does not have YSQL superuser privileges, but does have sufficient privileges for most tasks. For more information on database roles and privileges in Yugabyte Cloud, refer to Database authorization in Yugabyte Cloud clusters.
After the cluster is provisioned, you can add more users.
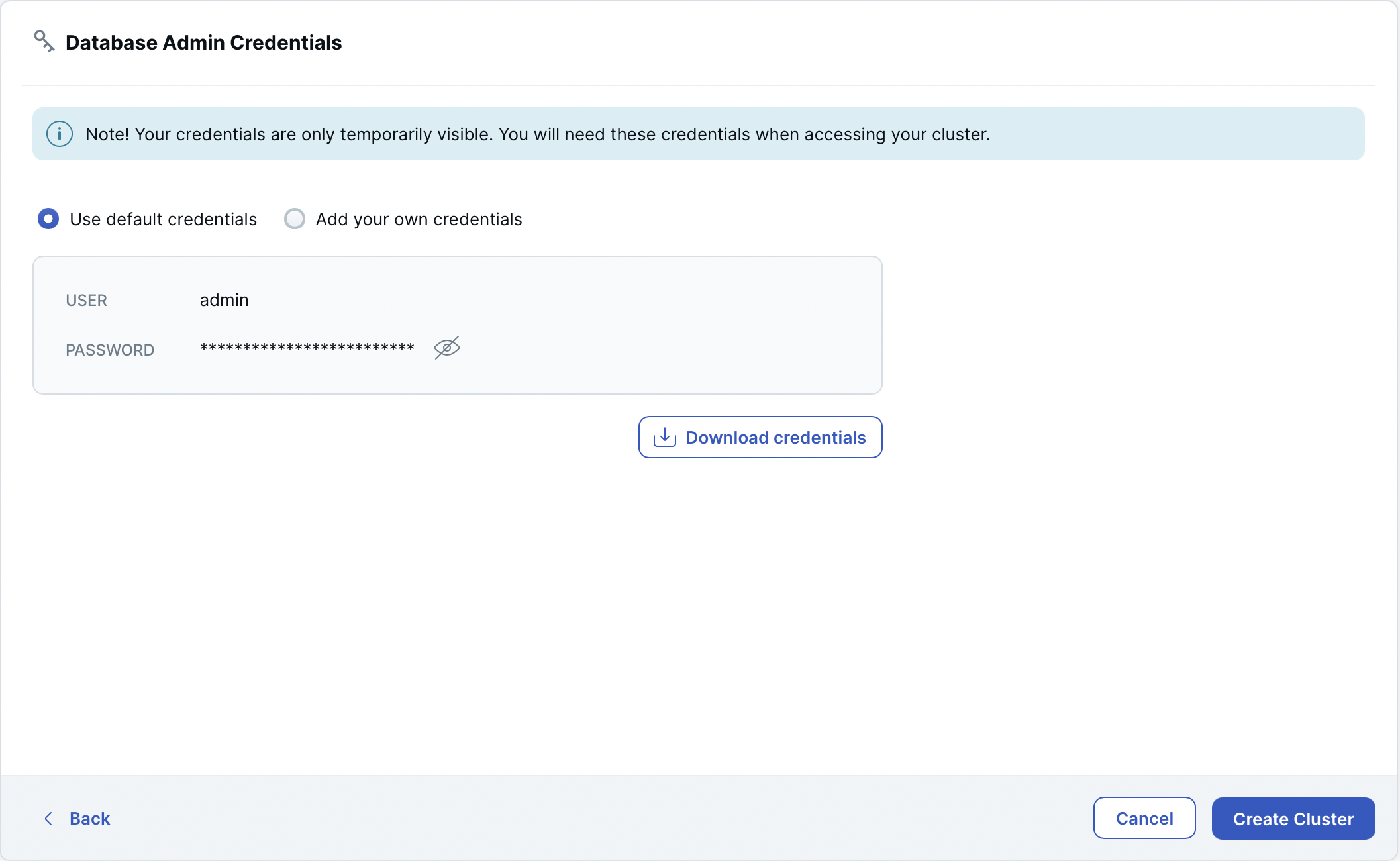
Download the credentials, and click Create Cluster.
Important
Save your database credentials. If you lose them, you won't be able to use the database.Viewing the cluster
After you complete the wizard, the Clusters page appears, showing the provisioning of your new cluster in progress.
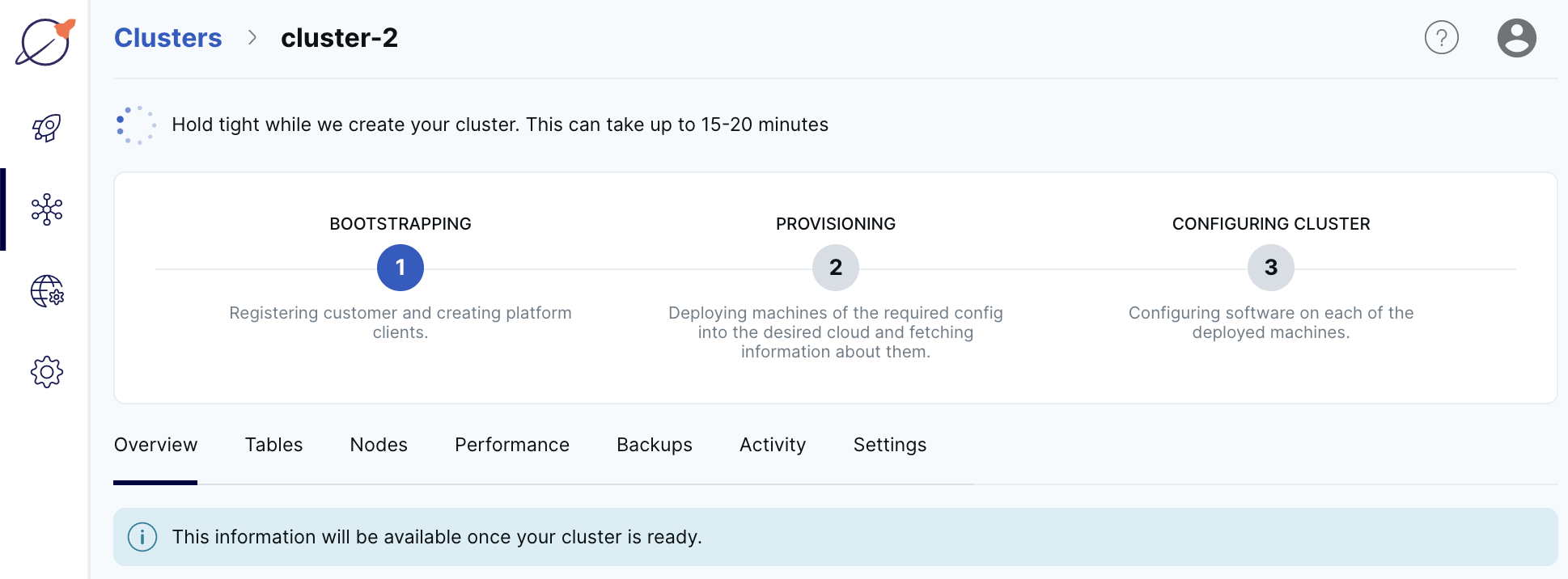
When the cluster is ready, the cluster Overview tab is displayed.
You now have a fully configured YugabyteDB cluster provisioned in Yugabyte Cloud with the database admin credentials you specified.