Follower reads
With YugabyteDB, you can use follower reads to lower read latencies since the DB now has less work to do at read time including serving the read from the tablet followers. Follower reads is similar to reading from a cache, which can give more read IOPS with low latency but might have slightly stale yet timeline-consistent data (that is, no out of order is possible). In this tutorial, you will update a single key-value over and over, and read it from the tablet leader. While that workload is running, you will start another workload to read from a follower and verify that you are able to read from a tablet follower.
YugabyteDB also allows you to specify the maximum staleness of data when reading from tablet followers. If the follower hasn't heard from the leader for 10 seconds (by default), the read request is forwarded to the leader. When there is a long distance between the tablet follower and the tablet leader, you might need to increase the duration. To change the duration for maximum staleness, add the yb-tserver --max_stale_read_bound_time_ms flag and increase the value (default is 10 seconds). For details on how to add this flag when using yb-ctl, see Creating a local cluster with custom flags.
1. Create universe
If you have a previously running local universe, destroy it by executing the following command:
$ ./bin/yb-ctl destroy
Start a new local universe with three nodes and a replication factor (RF) of 3, as follows:
$ ./bin/yb-ctl --rf 3 create
Add one more node, as follows:
$ ./bin/yb-ctl add_node
2. Write some data
Download the YugabyteDB workload generator JAR file (yb-sample-apps.jar) by running the following command:
$ wget https://github.com/yugabyte/yb-sample-apps/releases/download/1.3.9/yb-sample-apps.jar?raw=true -O yb-sample-apps.jar
By default, the YugabyteDB workload generator runs with strong read consistency, where all data is read from the tablet leader. We are going to populate exactly one key with a 10KB value into the system. Since the replication factor is 3, this key will get replicated to only three of the four nodes in the universe.
Run the CassandraKeyValue workload application to constantly update this key-value, as well as perform reads with strong consistency against the local universe, as follows:
$ java -jar ./yb-sample-apps.jar --workload CassandraKeyValue \
--nodes 127.0.0.1:9042 \
--nouuid \
--num_unique_keys 1 \
--num_threads_write 1 \
--num_threads_read 1 \
--value_size 10240
In the preceding command, the value of num_unique_keys is set to 1, which means a single key key:0 was overwritten. You can verify this using ycqlsh as follows:
$ ./bin/ycqlsh 127.0.0.1
Connected to local cluster at 127.0.0.1:9042.
[ycqlsh 5.0.1 | Cassandra 3.9-SNAPSHOT | CQL spec 3.4.2 | Native protocol v4]
Use HELP for help.
Run a query as follows:
ycqlsh> SELECT k FROM ybdemo_keyspace.cassandrakeyvalue;
k
-------
key:0
(1 rows)
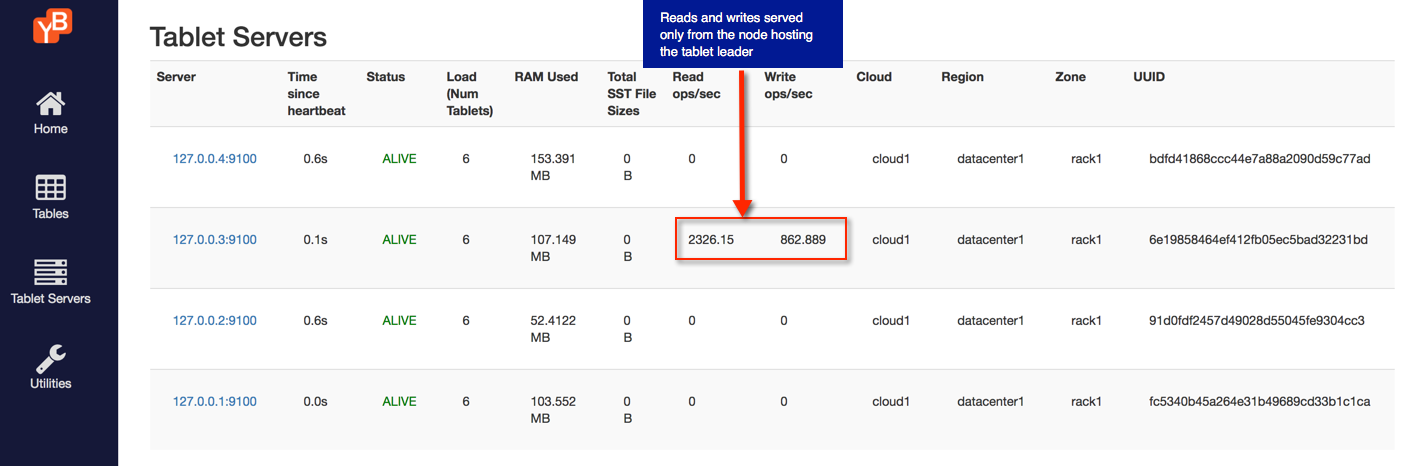
3. Strongly consistent reads from tablet leaders
When performing strongly consistent reads as a part of the above command, all reads will be served by the tablet leader of the tablet that contains the key key:0. If you browse to the tablet-servers page, you will see that all the requests are indeed being served by one tserver, as shown in the following illustration:
4. Follower reads from tablet replicas
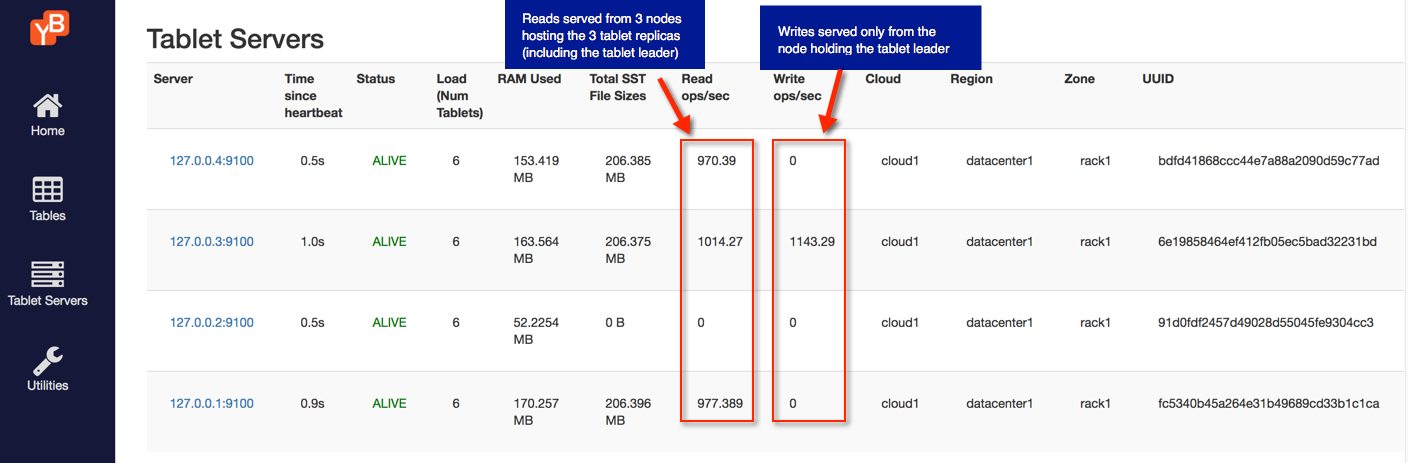
Stop the workload application above, and then run the following variant of that workload application. This command will do updates to the same key key:0 which will go through the tablet leader, but it will reads from the replicas, as follows:
$ java -jar ./yb-sample-apps.jar --workload CassandraKeyValue \
--nodes 127.0.0.1:9042 \
--nouuid \
--num_unique_keys 1 \
--num_threads_write 1 \
--num_threads_read 1 \
--value_size 10240 \
--local_reads
This can be easily seen by refreshing the tablet-servers page, where you will see that the writes are served by a single YB-TServer that is the leader of the tablet for the key key:0 while multiple YB-TServers which are replicas serve the reads.
5. Clean up (optional)
Optionally, you can execute the following command to shut down the local cluster created in Step 1:
$ ./bin/yb-ctl destroy