IoT fleet management
Overview
This is an end-to-end functional application with source code and installation instructions available on GitHub. It is a blueprint for an IoT application built on top of YugabyteDB (using the Cassandra-compatible YCQL API) as the database, Confluent Kafka as the message broker, KSQL or Apache Spark Streaming for real-time analytics and Spring Boot as the application framework.
Scenario
Assume that a fleet management company wants to track their fleet of vehicles which are delivering shipments. The vehicles performing the shipments are of different types (18 Wheelers, buses, large trucks, etc), and the shipments themselves happen over 3 routes (Route-37, Route-82, Route-43). The company wants to track:
- the breakdown of their vehicle types per shipment delivery route
- which vehicles are near road closures so that they can predict delays in deliveries
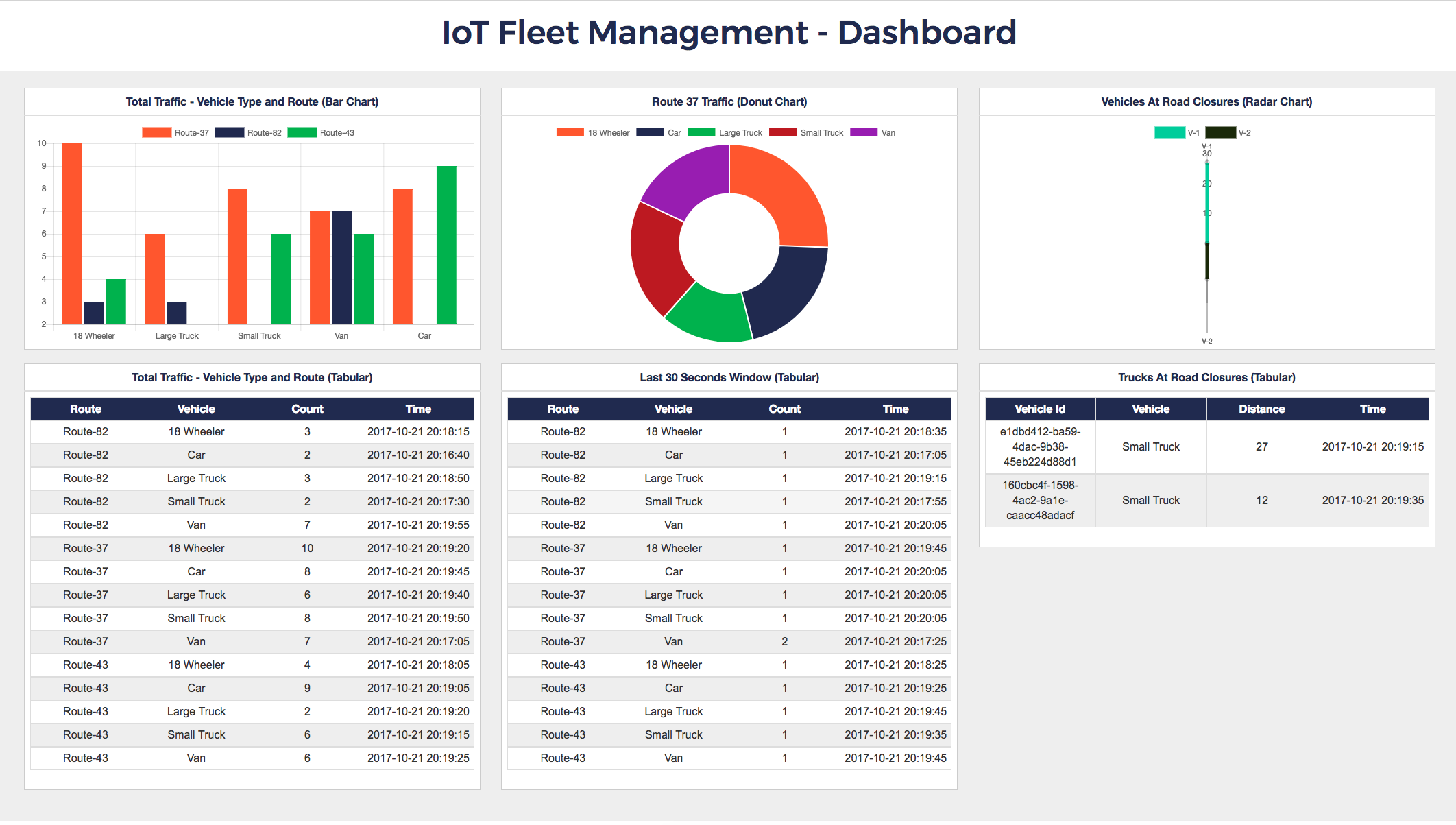
This app renders a dashboard showing both of the above. Below is a view of the real-time, auto-refreshing dashboard.
Application architecture
This application has the following subcomponents:
- Data Store - YugabyteDB for storing raw events from Kafka as well as the aggregates from the Data Processor
- Data Producer - Test program writing into Kafka
- Data Processor - KSQL or Apache Spark Streaming reading from Kafka, computing the aggregates and store results in the Data Store
- Data Dashboard - Spring Boot app using web sockets, jQuery and bootstrap
We will look at each of these components in detail. Below is an architecture diagram showing how these components fit together.
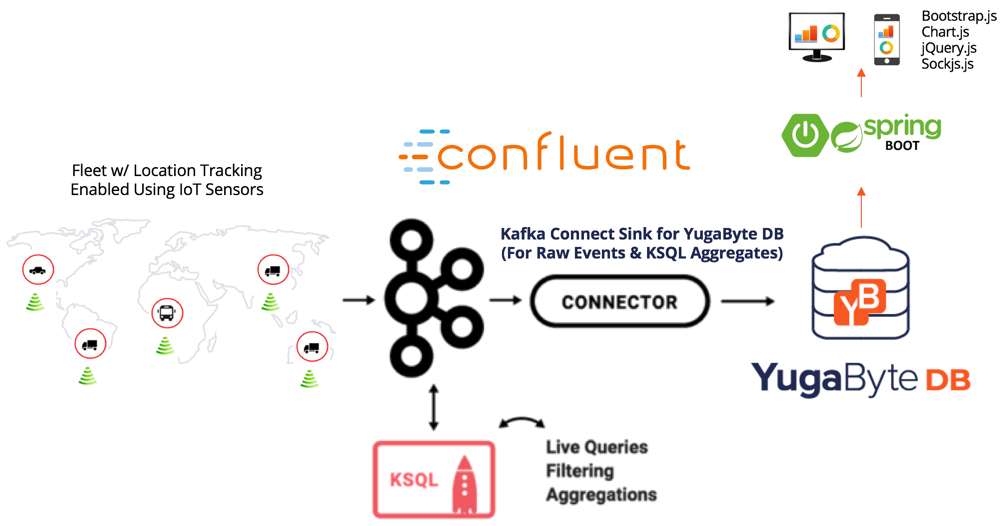
Confluent Kafka, KSQL, and YugabyteDB (CKY Stack)
App architecture with the CKY stack is shown below. The same Kafka Connect Sink Connector for YugabyteDB is used for storing both the raw events as well as the aggregate data (that's generated using KSQL).
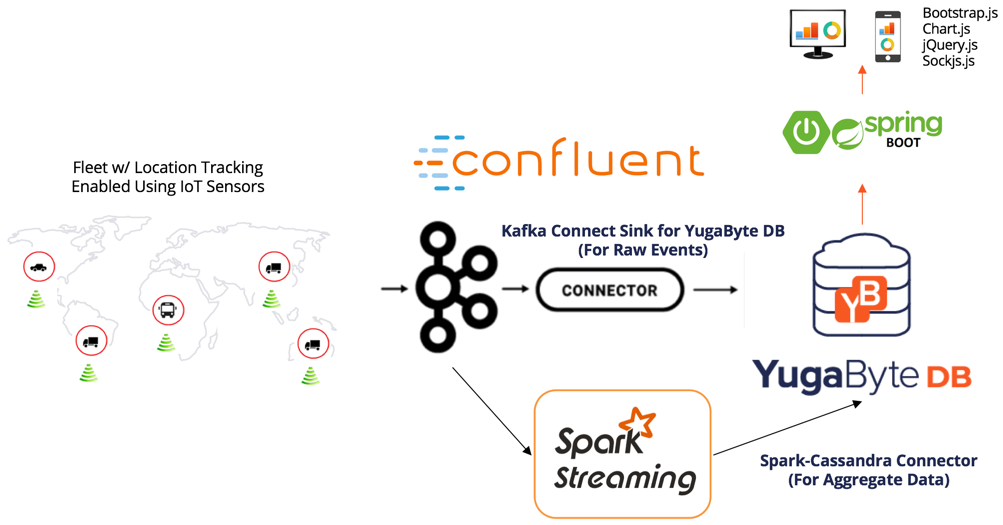
Spark, Kafka, and YugabyteDB (SKY Stack)
App architecture with the SKY stack is shown below. The Kafka Connect Sink Connector for YugabyteDB is used for storing raw events from Kafka to YugabyteDB. The aggregate data generated via Apache Spark Streaming is persisted in YugabyteDB using the Spark-Cassandra Connector.
Data store
Stores all the user-facing data. YugabyteDB is used here, with the Cassandra-compatible YCQL as the programming language.
All the data is stored in the keyspace TrafficKeySpace:
CREATE KEYSPACE IF NOT EXISTS TrafficKeySpace
There is one table for storing the raw events. Note the default_time_to_live value below to ensure that raw events get auto-expired after the specified period of time. This is to ensure that the raw events do not consume up all the storage in the database and efficiently deleted from the database a short while after their aggregates have been computed.
CREATE TABLE TrafficKeySpace.Origin_Table (
vehicleId text,
routeId text,
vehicleType text,
longitude text,
latitude text,
timeStamp timestamp,
speed double,
fuelLevel double,
PRIMARY KEY ((vehicleId), timeStamp))
WITH default_time_to_live = 3600;
There are three tables that hold the user-facing data - Total_Traffic for the lifetime traffic information, Window_Traffic for the last 30 seconds of traffic and poi_traffic for the traffic near a point of interest (road closures). The data processor constantly updates these tables, and the dashboard reads from these tables. Below are the schemas for these tables.
CREATE TABLE TrafficKeySpace.Total_Traffic (
routeId text,
vehicleType text,
totalCount bigint,
timeStamp timestamp,
recordDate text,
PRIMARY KEY (routeId, recordDate, vehicleType)
);
CREATE TABLE TrafficKeySpace.Window_Traffic (
routeId text,
vehicleType text,
totalCount bigint,
timeStamp timestamp,
recordDate text,
PRIMARY KEY (routeId, recordDate, vehicleType)
);
CREATE TABLE TrafficKeySpace.poi_traffic(
vehicleid text,
vehicletype text,
distance bigint,
timeStamp timestamp,
PRIMARY KEY (vehicleid)
);
Data producer
A program that generates random test data and publishes it to the Kafka topic iot-data-event. This emulates the data received from the connected vehicles using a message broker in the real world.
A single data point is a JSON payload and looks as follows:
{
"vehicleId":"0bf45cac-d1b8-4364-a906-980e1c2bdbcb",
"vehicleType":"Taxi",
"routeId":"Route-37",
"longitude":"-95.255615",
"latitude":"33.49808",
"timestamp":"2017-10-16 12:31:03",
"speed":49.0,
"fuelLevel":38.0
}
The Kafka Connect Sink Connector for YugabyteDB reads the above iot-data-event topic, transforms the event into a YCQL INSERT statement and then calls YugabyteDB to persist the event in the TrafficKeySpace.Origin_Table table.
Data processor
KSQL
KSQL is the open source streaming SQL engine for Apache Kafka. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python. It supports a wide range of streaming operations, including data filtering, transformations, aggregations, joins, windowing, and sessionization.
The first step in using KSQL is to create a stream from the raw events as shown below.
CREATE STREAM traffic_stream (
vehicleId varchar,
vehicleType varchar,
routeId varchar,
timeStamp varchar,
latitude varchar,
longitude varchar)
WITH (
KAFKA_TOPIC='iot-data-event',
VALUE_FORMAT='json',
TIMESTAMP='timeStamp',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss');
Various aggregations/queries can now be run on the above stream with results of each type of query stored in a topic of its own. This application uses 3 such queries/topics. Thereafter, the Kafka Connect Sink Connector for YugabyteDB reads these 3 topics and persists the results into the 3 corresponding tables in YugabyteDB.
CREATE TABLE total_traffic
WITH ( PARTITIONS=1,
KAFKA_TOPIC='total_traffic',
TIMESTAMP='timeStamp',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss') AS
SELECT routeId,
vehicleType,
count(vehicleId) AS totalCount,
max(rowtime) AS timeStamp,
TIMESTAMPTOSTRING(max(rowtime), 'yyyy-MM-dd') AS recordDate
FROM traffic_stream
GROUP BY routeId, vehicleType;
CREATE TABLE window_traffic
WITH ( TIMESTAMP='timeStamp',
KAFKA_TOPIC='window_traffic',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss',
PARTITIONS=1) AS
SELECT routeId,
vehicleType,
count(vehicleId) AS totalCount,
max(rowtime) AS timeStamp,
TIMESTAMPTOSTRING(max(rowtime), 'yyyy-MM-dd') AS recordDate
FROM traffic_stream
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS)
GROUP BY routeId, vehicleType;
CREATE STREAM poi_traffic
WITH ( PARTITIONS=1,
KAFKA_TOPIC='poi_traffic',
TIMESTAMP='timeStamp',
TIMESTAMP_FORMAT='yyyy-MM-dd HH:mm:ss') AS
SELECT vehicleId,
vehicleType,
cast(GEO_DISTANCE(cast(latitude AS double),cast(longitude AS double),33.877495,-95.50238,'KM') AS bigint) AS distance,
timeStamp
FROM traffic_stream
WHERE GEO_DISTANCE(cast(latitude AS double),cast(longitude AS double),33.877495,-95.50238,'KM') < 30;
Apache Spark streaming
As an alternative to KSQL, you can use Apache Spark - a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
Below is a sample Apache Spark streaming application (Java) that consumes the data stream from a Kafka topic, converts it into meaningful insights and writes the resulting aggregate data to YugabyteDB via a DataStax Spark Cassandra Connector.
Set up the Spark Cassandra Connector:
SparkConf conf = new SparkConf()
.setAppName(prop.getProperty("com.iot.app.spark.app.name"))
.setMaster(prop.getProperty("com.iot.app.spark.master"))
.set("spark.cassandra.connection.host", cassandraHost)
.set("spark.cassandra.connection.port", cassandraPort)
.set("spark.cassandra.connection.keep_alive_ms", prop.getProperty("com.iot.app.cassandra.keep_alive"));
The data is consumed from a Kafka stream and collected in 5 second batches:
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
JavaPairInputDStream<String, IoTData> directKafkaStream =
KafkaUtils.createDirectStream(jssc,
String.class,
IoTData.class,
StringDecoder.class,
IoTDataDecoder.class,
kafkaParams,
topicsSet
);
Create non-filtered and filtered streams, to be used later in actual processing:
// Non-filtered stream for Point-of-interest (POI) traffic data calculation
JavaDStream<IoTData> nonFilteredIotDataStream = directKafkaStream.map(tuple -> tuple._2());
// Filtered stream for total and traffic data calculation
JavaPairDStream<String,IoTData> iotDataPairStream =
nonFilteredIotDataStream.mapToPair(iot -> new Tuple2<String,IoTData>(iot.getVehicleId(),iot)).reduceByKey((a, b) -> a );
// Check vehicle ID is already processed
JavaMapWithStateDStream<String, IoTData, Boolean, Tuple2<IoTData,Boolean>> iotDStreamWithStatePairs =
iotDataPairStream.mapWithState(
StateSpec.function(processedVehicleFunc).timeout(Durations.seconds(3600)) // Maintain state for one hour
);
// Filter processed vehicle IDs and keep un-processed
JavaDStream<Tuple2<IoTData,Boolean>> filteredIotDStreams =
iotDStreamWithStatePairs.map(tuple2 -> tuple2).filter(tuple -> tuple._2.equals(Boolean.FALSE));
// Get stream of IoTData
JavaDStream<IoTData> filteredIotDataStream = filteredIotDStreams.map(tuple -> tuple._1);
The above code uses the following function to check for processed vehicles:
Function3<String, Optional<IoTData>, State<Boolean>, Tuple2<IoTData, Boolean>> processedVehicleFunc = (String, iot, state) -> {
Tuple2<IoTData,Boolean> vehicle = new Tuple2<>(iot.get(), false);
if (state.exists()) {
vehicle = new Tuple2<>(iot.get(), true);
}
else {
state.update(Boolean.TRUE);
}
return vehicle;
};
Compute a breakdown by vehicle type and the shipment route across all the vehicles and shipments done so far:
// Get count of vehicle group by routeId and vehicleType
JavaPairDStream<AggregateKey, Long> countDStreamPair =
filteredIotDataStream
.mapToPair(iot -> new Tuple2<>(new AggregateKey(iot.getRouteId(), iot.getVehicleType()), 1L))
.reduceByKey((a, b) -> a + b);
// Keep state for total count
JavaMapWithStateDStream<AggregateKey, Long, Long, Tuple2<AggregateKey, Long>> countDStreamWithStatePair =
countDStreamPair.mapWithState(
StateSpec.function(totalSumFunc).timeout(Durations.seconds(3600)) // Maintain state for one hour
);
// Transform to DStream of TrafficData
JavaDStream<Tuple2<AggregateKey, Long>> countDStream = countDStreamWithStatePair.map(tuple2 -> tuple2);
JavaDStream<TotalTrafficData> trafficDStream = countDStream.map(totalTrafficDataFunc);
// Map Cassandra table column
Map<String, String> columnNameMappings = new HashMap<String, String>();
columnNameMappings.put("routeId", "routeid");
columnNameMappings.put("vehicleType", "vehicletype");
columnNameMappings.put("totalCount", "totalcount");
columnNameMappings.put("timeStamp", "timestamp");
columnNameMappings.put("recordDate", "recorddate");
// Call CassandraStreamingJavaUtil function to save in database
javaFunctions(trafficDStream)
.writerBuilder("traffickeyspace", "total_traffic", CassandraJavaUtil.mapToRow(TotalTrafficData.class, columnNameMappings))
.saveToCassandra();
Compute the same breakdown for active shipments. This is done by computing the breakdown by vehicle type and shipment route for the last 30 seconds:
// Reduce by key and window (30 sec window and 10 sec slide)
JavaPairDStream<AggregateKey, Long> countDStreamPair =
filteredIotDataStream
.mapToPair(iot -> new Tuple2<>(new AggregateKey(iot.getRouteId(), iot.getVehicleType()), 1L))
.reduceByKeyAndWindow((a, b) -> a + b, Durations.seconds(30), Durations.seconds(10));
// Transform to DStream of TrafficData
JavaDStream<WindowTrafficData> trafficDStream = countDStreamPair.map(windowTrafficDataFunc);
// Map Cassandra table column
Map<String, String> columnNameMappings = new HashMap<String, String>();
columnNameMappings.put("routeId", "routeid");
columnNameMappings.put("vehicleType", "vehicletype");
columnNameMappings.put("totalCount", "totalcount");
columnNameMappings.put("timeStamp", "timestamp");
columnNameMappings.put("recordDate", "recorddate");
// Call CassandraStreamingJavaUtil function to save in database
javaFunctions(trafficDStream)
.writerBuilder("traffickeyspace", "window_traffic", CassandraJavaUtil.mapToRow(WindowTrafficData.class, columnNameMappings))
.saveToCassandra();
Detect the vehicles which are within a 20 mile radius of a given Point of Interest (POI), which represents a road-closure:
// Filter by routeId, vehicleType and in POI range
JavaDStream<IoTData> iotDataStreamFiltered =
nonFilteredIotDataStream
.filter(iot -> (iot.getRouteId().equals(broadcastPOIValues.value()._2())
&& iot.getVehicleType().contains(broadcastPOIValues.value()._3())
&& GeoDistanceCalculator.isInPOIRadius(
Double.valueOf(iot.getLatitude()),
Double.valueOf(iot.getLongitude()),
broadcastPOIValues.value()._1().getLatitude(),
broadcastPOIValues.value()._1().getLongitude(),
broadcastPOIValues.value()._1().getRadius()
)
)
);
// Pair with POI
JavaPairDStream<IoTData, POIData> poiDStreamPair =
iotDataStreamFiltered.mapToPair(iot -> new Tuple2<>(iot, broadcastPOIValues.value()._1()));
// Transform to DStream of POITrafficData
JavaDStream<POITrafficData> trafficDStream = poiDStreamPair.map(poiTrafficDataFunc);
// Map Cassandra table column
Map<String, String> columnNameMappings = new HashMap<String, String>();
columnNameMappings.put("vehicleId", "vehicleid");
columnNameMappings.put("distance", "distance");
columnNameMappings.put("vehicleType", "vehicletype");
columnNameMappings.put("timeStamp", "timestamp");
// Call CassandraStreamingJavaUtil function to save in database
javaFunctions(trafficDStream)
.writerBuilder("traffickeyspace", "poi_traffic", CassandraJavaUtil.mapToRow(POITrafficData.class, columnNameMappings))
.withConstantTTL(120) // Keeping data for 2 minutes
.saveToCassandra();
The above "detection within radius" code uses the following helper functions:
// Function to get running sum by maintaining the state
Function3<AggregateKey, Optional<Long>, State<Long>, Tuple2<AggregateKey, Long>> totalSumFunc = (key, currentSum, state) -> {
long totalSum = currentSum.or(0L) + (state.exists() ? state.get() : 0);
Tuple2<AggregateKey, Long> total = new Tuple2<>(key, totalSum);
state.update(totalSum);
return total;
};
// Function to create TotalTrafficData object from IoT data
Function<Tuple2<AggregateKey, Long>, TotalTrafficData> totalTrafficDataFunc = (tuple -> {
TotalTrafficData trafficData = new TotalTrafficData();
trafficData.setRouteId(tuple._1().getRouteId());
trafficData.setVehicleType(tuple._1().getVehicleType());
trafficData.setTotalCount(tuple._2());
trafficData.setTimeStamp(new Date());
trafficData.setRecordDate(new SimpleDateFormat("yyyy-MM-dd").format(new Date()));
return trafficData;
});
// Function to create WindowTrafficData object from IoT data
Function<Tuple2<AggregateKey, Long>, WindowTrafficData> windowTrafficDataFunc = (tuple -> {
WindowTrafficData trafficData = new WindowTrafficData();
trafficData.setRouteId(tuple._1().getRouteId());
trafficData.setVehicleType(tuple._1().getVehicleType());
trafficData.setTotalCount(tuple._2());
trafficData.setTimeStamp(new Date());
trafficData.setRecordDate(new SimpleDateFormat("yyyy-MM-dd").format(new Date()));
return trafficData;
});
// Function to create POITrafficData object from IoT data
Function<Tuple2<IoTData, POIData>, POITrafficData> poiTrafficDataFunc = (tuple -> {
POITrafficData poiTraffic = new POITrafficData();
poiTraffic.setVehicleId(tuple._1.getVehicleId());
poiTraffic.setVehicleType(tuple._1.getVehicleType());
poiTraffic.setTimeStamp(new Date());
double distance = GeoDistanceCalculator.getDistance(
Double.valueOf(tuple._1.getLatitude()).doubleValue(),
Double.valueOf(tuple._1.getLongitude()).doubleValue(),
tuple._2.getLatitude(),
tuple._2.getLongitude()
);
poiTraffic.setDistance(distance);
return poiTraffic;
});
Data dashboard
This is a Spring Boot application which queries the data from YugabyteDB and pushes the data to the webpage using Web Sockets and jQuery. The data is pushed to the web page in fixed intervals so data will be refreshed automatically. Dashboard displays data in charts and tables. This web page uses bootstrap.js to display the dashboard containing charts and tables.
We create entity classes for the three tables Total_Traffic, Window_Traffic and Poi_Traffic, and DAO interfaces for all the entities extending CassandraRepository. For example, you create the DAO class for TotalTrafficData entity as follows.
@Repository
public interface TotalTrafficDataRepository extends CassandraRepository<TotalTrafficData> {
@Query("SELECT * FROM traffickeyspace.total_traffic WHERE recorddate = ? ALLOW FILTERING")
Iterable<TotalTrafficData> findTrafficDataByDate(String date);
}
In order to connect to YugabyteDB cluster and get connection for database operations, you write the CassandraConfig class. This is done as follows:
public class CassandraConfig extends AbstractCassandraConfiguration {
@Bean
public CassandraClusterFactoryBean cluster() {
// Create a Cassandra cluster to access YugabyteDB using CQL.
CassandraClusterFactoryBean cluster = new CassandraClusterFactoryBean();
// Set the database host.
cluster.setContactPoints(environment.getProperty("com.iot.app.cassandra.host"));
// Set the database port.
cluster.setPort(Integer.parseInt(environment.getProperty("com.iot.app.cassandra.port")));
return cluster;
}
}
Note that currently the Dashboard does not use the raw events table and relies only on the data stored in the aggregates tables.
Summary
This application is a blueprint for building IoT applications. The instructions to build and run the application, as well as the source code can be found in the IoT Fleet Management GitHub repository.