SQL vs NoSQL
Most application developers have used SQL, and possibly some NoSQL databases, to build applications. YugabyteDB brings the best of these two databases together into one unified platform to simplify development of scalable cloud services.
Very often, today's cloud services and applications will start out with just a few requests and a very small amount of data. These can be served by just a few nodes. But if the application becomes popular, they would have to scale out rapidly in order to handle millions of requests and many terabytes of data. YugabyteDB is well suited for these kinds of workloads.
Unifying SQL and NoSQL
Here are a few different criteria where YugabyteDB brings the best of SQL and NoSQL together into a single database platform.
Data characteristics
These can be loosely defined as the high-level concerns when choosing a database to build an application or a cloud service - such as its data model, the API it supports, its consistency semantics and so on. Here is a table that contrasts what YugabyteDB offers with SQL and NoSQL databases in general. Note that there are a number of different NoSQL databases each with their own nuanced behavior, and the table below is not accurate for all NoSQL databases - it is just meant to give an idea.
| Database characteristics | SQL | NoSQL | YugabyteDB |
|---|---|---|---|
| Data model | Well-defined schema (tables, rows, columns) | Schemaless | Both |
| API | SQL | Various | Fully-relational SQL + Semi-relational SQL |
| Consistency | Strong consistency | Eventual consistency | Strong consistency |
| Transactions | ACID transactions | No transactions | ACID transactions |
| High Write Throughput | No | Sometimes | Yes |
| Tunable read latency | No | Yes | Yes |
Operational characteristics
Operational characteristics can be defined as the runtime concerns that arise when a database is deployed, run and managed in production. When running a database in production in a cloud-like architecture, there are a number of operational characteristics that become essential. Operationally here are the capabilities of YugabyteDB compared to SQL and NoSQL databases. As before, there are a number of NoSQL databases which are different in their own ways and the table below is meant to give a broad idea.
| Operational characteristics | SQL | NoSQL | YugabyteDB |
|---|---|---|---|
| Automatic sharding | No | Sometimes | Yes |
| Linear scalability | No | Yes | Yes |
| Fault tolerance | No - manual setup | Yes - smart client detects failed nodes | Yes - smart client detects failed nodes |
| Data resilience | No | Yes - but rebuilds cause high latencies | Yes - automatic, efficient data rebuilds |
| Geo-distributed | No - manual setup | Sometimes | Yes |
| Low latency reads | No | Yes | Yes |
| Predictable p99 read latency | Yes | No | Yes |
| High data density | No | Sometimes - latencies suffer when densities increase | Yes - predictable latencies at high data densities |
| Tunable reads with timeline consistency | No - manual setup | Sometimes | Yes |
| Read replica support | No - manual setup | No - no async replication | Yes - sync and async replication options |
Core features
Applications and cloud services depend on databases for a variety of built-in features. These can include the ability to perform multi-row transactions, JSON or document support, secondary indexes, automatic data expiration with TTLs, and so on.
Here is a table that lists some of the important features that YugabyteDB supports, and which of YugabyteDB's APIs to use in order to achieve these features. Note that typically, multiple databases are deployed in order to achieve these features.
| Database features | Yugabyte SQL API | Yugabyte Cloud QL API |
|---|---|---|
| Multi-row transactions | Yes | Yes |
| Consistent secondary indexes | Yes | Yes |
| JSON/document support | Yes | Yes |
| Secondary Indexes | Yes | Yes |
| Foreign keys | Yes | No |
| JOINs | Yes | No |
| Automatic data expiry with TTL | No | Yes - table and column level TTL |
| Run Apache Spark for AI/ML | No | Yes |
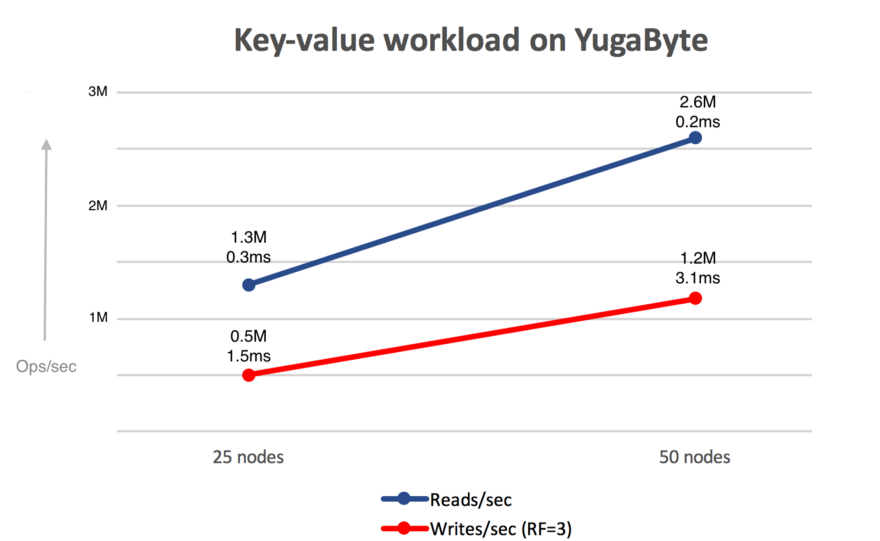
Linear scalability
In order to test the linear scalability of YugabyteDB, we have run some large cluster benchmarks (up to 50 nodes). We were able to scale YugabyteDB to million of reads and writes per second while retaining low latencies. You can read more about our large cluster tests and how we scaled YugabyteDB to millions of IOPS.
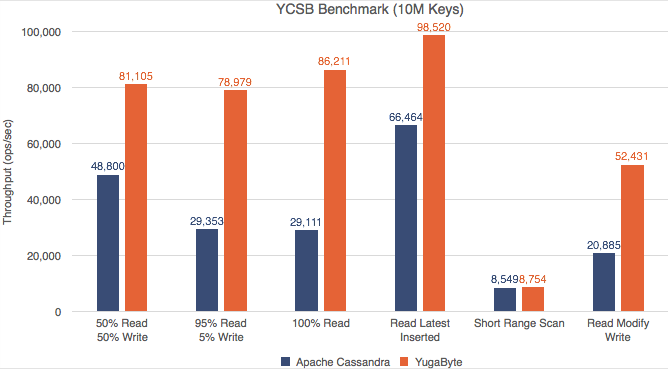
High performance
YugabyteDB was built with a performance as a design goal. Performance in a public cloud environment without sacrificing consistency is a serious ask. YugabyteDB has been written in C++ for this very reason. Here is a chart showing how YugabyteDB compares with Apache Cassandra when running a YCSB benchmark. Read more about the YCSB benchmark results and what makes YugabyteDB performant.
The first chart below shows the total ops/second when running YBSB benchmark.
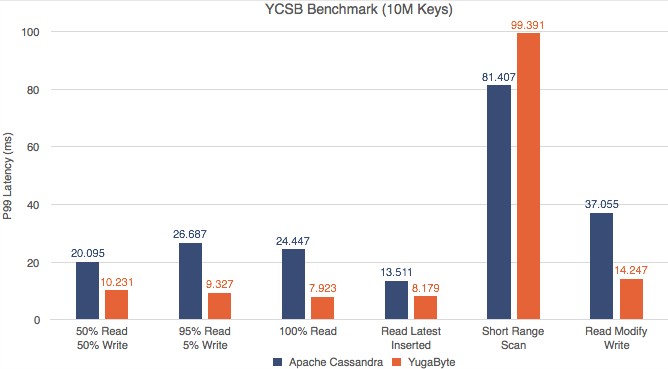
The second chart below shows the latency for the YCSB run.
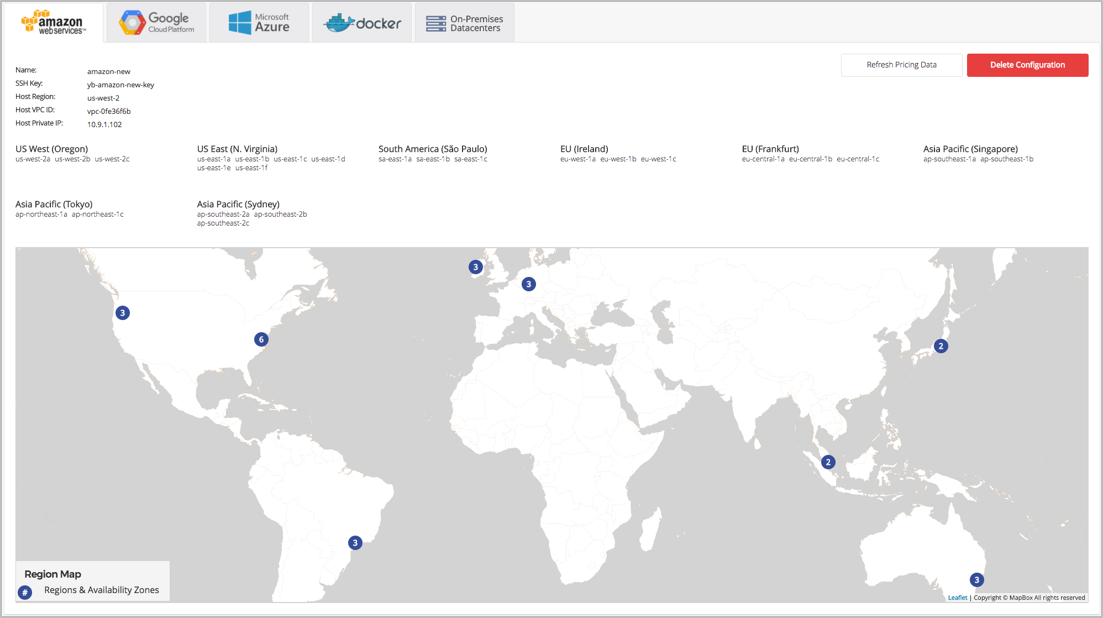
Geo-distributed
This is a screenshot of YugabyteDB EE, which visualized the universe created. Below is a screenshot of a 5-node YugabyteDB universe created for a user identity use-case to power users logging in and changing passwords for a SaaS application. The replication factor of this universe is 5, and it is configured to keep 2 copies of data in us-west, 2 copies of the data in us-east and 1 copy of the data in the Asia-Pacific region.
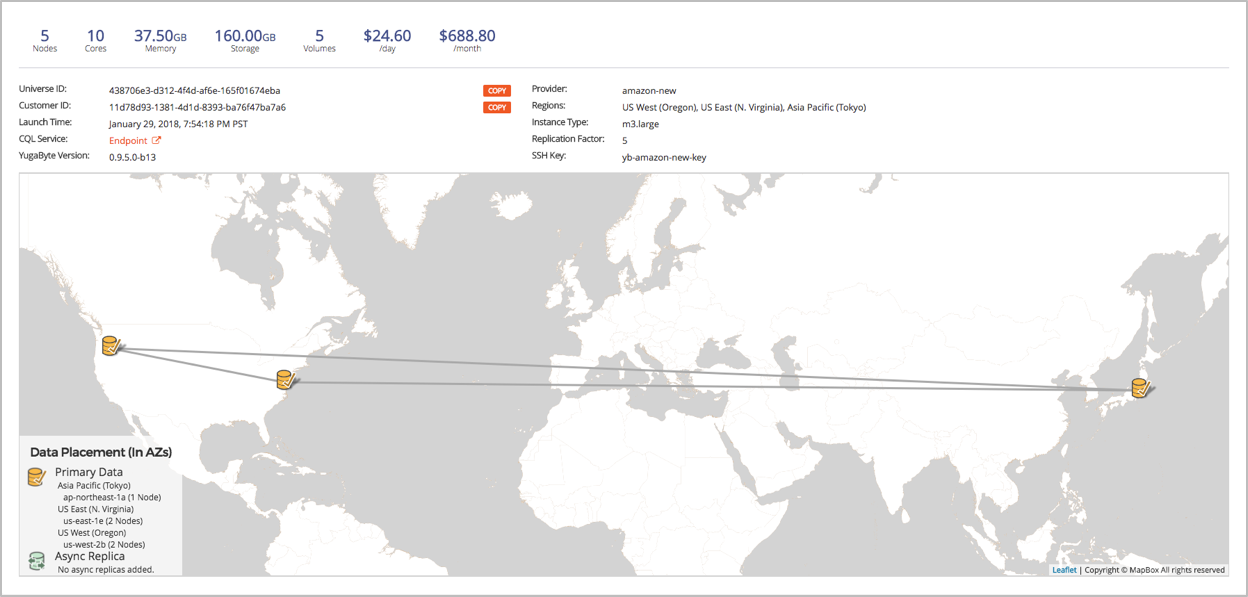
Because of this configuration, this universe can:
- Allow low read latencies from any region (follower reads from a nearby data center)
- Allow strongly consistent, global writes
- Survive the outage of any region
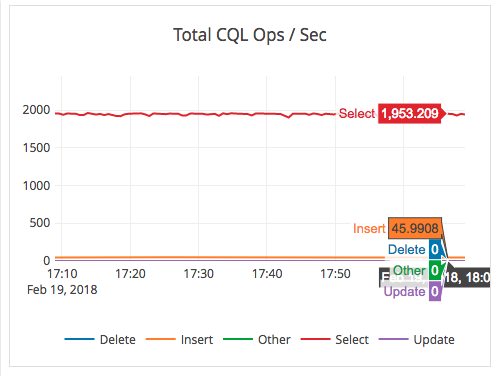
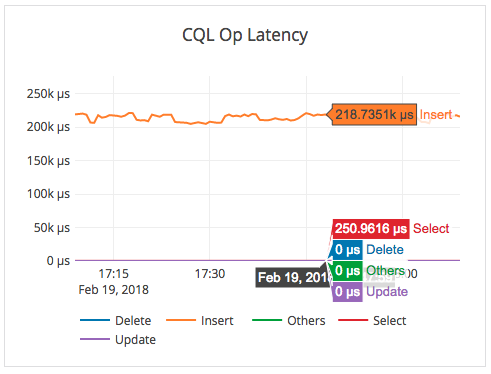
The graphs above, also taken from the EE, show that the average read latencies for apps running the various cloud regions are just 250 microseconds, while writes are strongly consistent and incur 218 milliseconds.
Multi-cloud ready
It is possible to easily configure YugabyteDB EE to work with multiple public clouds as well as private data centers in just a few minutes.