Asynchronous Replication
You can perform deployment using unidirectional (master-follower) or bidirectional (multi-master) asynchronous replication between universes (also known as data centers).
For information on two data center (2DC) deployment architecture and supported replication scenarios, see Two data center (2DC) deployments.
Setting Up Universes
You can create source and target universes as follows:
- Create the yugabyte-source universe by following the procedure from Manual deployment.
- Create tables for the APIs being used by the source universe.
- Create the yugabyte-target universe by following the procedure from Manual deployment.
- Create tables for the APIs being used by the target universe. These should be the same tables as you created for the source universe.
- Proceed to setting up unidirectional or bidirectional replication.
Note
In case you already have existing data in your tables, you will need to follow the bootstrap process bootstrapping a sink cluster.Setting Up Unidirectional Replication
After you created the required tables, you can set up asynchronous replication as follows:
-
Look up the source universe UUID and the table IDs for the two tables and the index table:
-
To find a universe's UUID, check
/varzfor--cluster_uuid. If it is not available in this location, check the same field in the cluster configuration. -
To find a table ID, execute the following command as an admin user:
yb-admin list_tables include_table_id
-
-
Run the following
yb-adminsetup_universe_replicationcommand from the YugabyteDB home directory in the source universe:./bin/yb-admin \ -master_addresses <target_universe_master_addresses> \ setup_universe_replication <source_universe_uuid> \ <source_universe_master_addresses> \ <table_id>,[<table_id>..]For example:
./bin/yb-admin \ -master_addresses 127.0.0.11:7100,127.0.0.12:7100,127.0.0.13:7100 \ setup_universe_replication e260b8b6-e89f-4505-bb8e-b31f74aa29f3 \ 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \ 000030a5000030008000000000004000,000030a5000030008000000000004005,dfef757c415c4b2cacc9315b8acb539a
The preceding command contains three table IDs: the first two are YSQL for the base table and index, and the third is the YCQL table.
Also, be sure to specify all master addresses for source and target universes in the command.
If you need to set up bidirectional replication, see instructions provided in Setting Up Bidirectional Replication. Otherwise, proceed to Loading Data into the Source Universe.
Setting Up Bidirectional Replication
To set up bidirectional replication, repeat the procedure described in Setting Up Unidirectional Replication applying the steps to the yugabyte-target universe. You need to set up each yugabyte-source to consume data from yugabyte-target.
When completed, proceed to Loading Data.
Loading Data into the Source Universe
Once you have set up replication, load data into the source universe as follows:
-
Download the YugabyteDB workload generator JAR file
yb-sample-apps.jarfrom GitHub. -
Start loading data into yugabyte-source by following examples for YSQL or YCQL:
-
YSQL:
java -jar yb-sample-apps.jar --workload SqlSecondaryIndex --nodes 127.0.0.1:5433 -
YCQL:
java -jar yb-sample-apps.jar --workload CassandraBatchKeyValue --nodes 127.0.0.1:9042
Note that the IP address needs to correspond to the IP of any T-Servers in the cluster. -
-
For bidirectional replication, repeat the preceding step in the yugabyte-target universe.
When completed, proceed to Verifying Replication.
Verifying Replication
You can verify replication by stopping the workload and then using the COUNT(*) function on the yugabyte-target to yugabyte-source match.
Unidirectional Replication
For unidirectional replication, connect to the yugabyte-target universe using the YSQL shell (ysqlsh) or the YCQL shell (ycqlsh), and confirm that you can see the expected records.
Bidirectional Replication
For bidirectional replication, repeat the procedure described in Unidirectional Replication, but reverse the source and destination information, as follows:
- Run
yb-admin setup_universe_replicationon the yugabyte-target universe, pointing to yugabyte-source. - Use the workload generator to start loading data into the yugabyte-target universe.
- Verify replication from yugabyte-target to yugabyte-source.
To avoid primary key conflict errors, keep the key ranges for the two universes separate. This is done automatically by the applications included in the yb-sample-apps.jar.
Replication Lag
Replication lag is computed at the tablet level as follows:
replication lag = hybrid_clock_time - last_read_hybrid_time
hybrid_clock_time is the hybrid clock timestamp on the source's tablet-server, and last_read_hybrid_time is the hybrid clock timestamp of the latest record pulled from the source.
An example script determine_replication_lag.sh calculates the replication lag. The script requires the jq package.
The following example generates a replication lag summary for all tables on a cluster. You can also request an individual table.
./determine_repl_latency.sh -m 10.150.255.114,10.150.255.115,10.150.255.113
To obtain a summary of all command options, execute determine_repl_latency.sh -h .
Setting Up Replication with TLS
Source and Target Universes have the Same Certificates
If both universes use the same certificates, run yb-admin setup_universe_replication and include the -certs_dir_name flag. Setting that to the target universe's certificate directory will make replication use those certificates for connecting to both universes.
For example:
./bin/yb-admin -master_addresses 127.0.0.11:7100,127.0.0.12:7100,127.0.0.13:7100 \
-certs_dir_name /home/yugabyte/yugabyte-tls-config \
setup_universe_replication e260b8b6-e89f-4505-bb8e-b31f74aa29f3 \
127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \
000030a5000030008000000000004000,000030a5000030008000000000004005,dfef757c415c4b2cacc9315b8acb539a
Source and Target Universes have Different Certificates
When both universes use different certificates, you need to store the certificates for the producer universe on the target universe:
-
Ensure that
use_node_to_node_encryptionis set totrueon all masters and tservers on both the source and target. -
For each master and tserver on the target universe, set the gflag
certs_for_cdc_dirto the parent directory where you will store all the source universe's certs for replication. -
Find the certificate authority file used by the source universe (
ca.crt). This should be stored within the--certs_dir. -
Copy this file to each node on the target. It needs to be copied to a directory named:
<certs_for_cdc_dir>/<source_universe_uuid>.For example, if you previously set
certs_for_cdc_dir=/home/yugabyte/yugabyte_producer_certs, and the source universe's ID is00000000-1111-2222-3333-444444444444, then you would need to copy the cert file to/home/yugabyte/yugabyte_producer_certs/00000000-1111-2222-3333-444444444444/ca.crt. -
Finally, set up replication using
yb-admin setup_universe_replication, making sure to also set the-certs_dir_nameflag to the directory with the target universe's certificates (this should be different from the directory used in the previous steps).For example, if you have the target's certificates in
/home/yugabyte/yugabyte-tls-config, then you would run:./bin/yb-admin -master_addresses 127.0.0.11:7100,127.0.0.12:7100,127.0.0.13:7100 \ -certs_dir_name /home/yugabyte/yugabyte-tls-config \ setup_universe_replication 00000000-1111-2222-3333-444444444444 \ 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \ 000030a5000030008000000000004000,000030a5000030008000000000004005,dfef757c415c4b2cacc9315b8acb539a
Setting up Replication with Geo-partitioning
Create 2 universes (source and target) with same configurations (with same regions and zones) as below:
- Regions: EU(Paris), Asia Pacific(Mumbai) and US West(Oregon)
- Zones: eu-west-3a, ap-south-1a and us-west-2a
./bin/yb-ctl --rf 3 create --placement_info "cloud1.region1.zone1,cloud2.region2.zone2,cloud3.region3.zone3"
For Example:
./bin/yb-ctl --rf 3 create --placement_info "aws.us-west-2.us-west-2a,aws.ap-south-1.ap-south-1a,aws.eu-west-3.eu-west-3a"
Create tables, table spaces and partition tables at both the source and target:
For Example:
- Main table: transactions
- Table spaces: eu_ts, ap_ts and us_ts
- Partition Tables: transactions_eu, transactions_in and transactions_us
CREATE TABLE transactions (
user_id INTEGER NOT NULL,
account_id INTEGER NOT NULL,
geo_partition VARCHAR,
amount NUMERIC NOT NULL,
created_at TIMESTAMP DEFAULT NOW()
) PARTITION BY LIST (geo_partition);
CREATE TABLESPACE eu_ts WITH(
replica_placement='{"num_replicas": 1, "placement_blocks":
[{"cloud": "aws", "region": "eu-west-3","zone":"eu-west-3a", "min_num_replicas":1}]}');
CREATE TABLESPACE us_ts WITH(
replica_placement='{"num_replicas": 1, "placement_blocks":
[{"cloud": "aws", "region": "us-west-2","zone":"us-west-2a", "min_num_replicas":1}]}');
CREATE TABLESPACE ap_ts WITH(
replica_placement='{"num_replicas": 1, "placement_blocks":
[{"cloud": "aws", "region": "ap-south-1","zone":"ap-south-1a", "min_num_replicas":1}]}');
CREATE TABLE transactions_eu
PARTITION OF transactions
(user_id, account_id, geo_partition, amount, created_at,
PRIMARY KEY (user_id HASH, account_id, geo_partition))
FOR VALUES IN ('EU') TABLESPACE eu_ts;
CREATE TABLE transactions_in
PARTITION OF transactions
(user_id, account_id, geo_partition, amount, created_at,
PRIMARY KEY (user_id HASH, account_id, geo_partition))
FOR VALUES IN ('IN') TABLESPACE ap_ts;
CREATE TABLE transactions_us
PARTITION OF transactions
(user_id, account_id, geo_partition, amount, created_at,
PRIMARY KEY (user_id HASH, account_id, geo_partition))
DEFAULT TABLESPACE us_ts;
Steps to create Replication(Unidirectional):
- Collect child table UUIDs from source universe (partition tables, here transactions_eu, transactions_in and transactions_us) - these will be used while setting up replication. To collect table UUIDs, go to the
Tablessection in the Admin UI (127.0.0.1:7000).
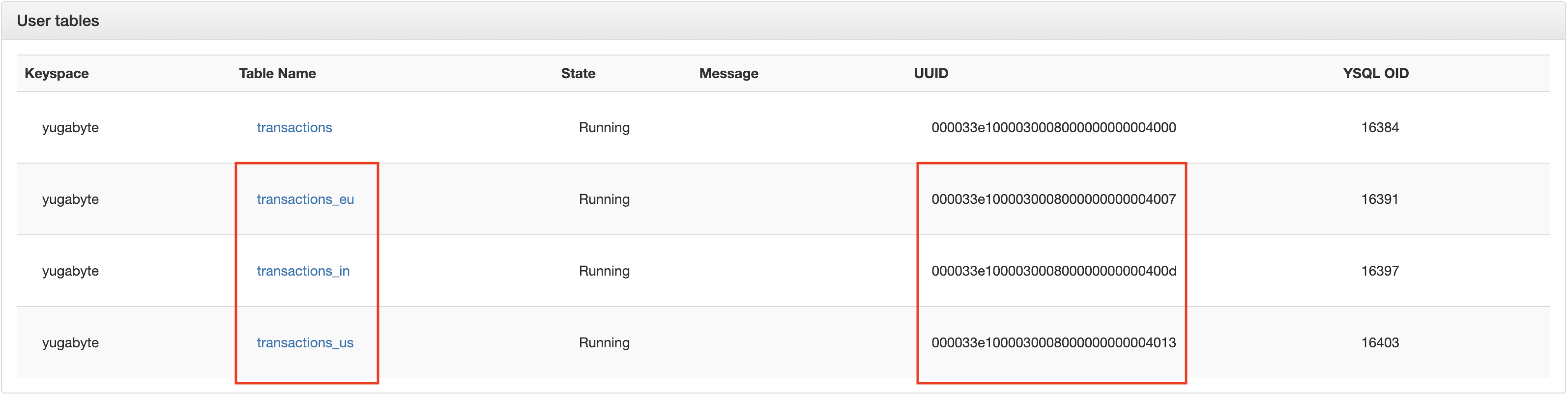
-
Run the replication setup command for the source universe:
./bin/yb-admin -master_addresses <consumer_master_addresses> \ setup_universe_replication <producer universe UUID>_<replication_stream_name> \ <producer_master_addresses> <comma_separated_table_ids>For Example:
./bin/yb-admin -master_addresses 127.0.0.11:7100,127.0.0.12:7100,127.0.0.13:7100 \ setup_universe_replication 00000000-1111-2222-3333-444444444444_xClusterSetup1 \ 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \ 000033e1000030008000000000004007,000033e100003000800000000000400d,000033e1000030008000000000004013 -
Observe replication setup(
xClusterSetup1) in Platform UI (At Replication tab in source universe and target universe)
xCluster Setup in K8s ( pod to pod connectivity )
- Create 2 universes (source and target).
- Create tables in both source and target universes
(At source)
kubectl exec -it -n <source_universe_namespace> -t <source_universe_master_leader> -c <source_universe_container> -- bash
/home/yugabyte/bin/ysqlsh -h <source_universe_yqlserver>
create table query
For Example:
kubectl exec -it -n xcluster-source -t yb-master-2 -c yb-master -- bash
/home/yugabyte/bin/ysqlsh -h yb-tserver-1.yb-tservers.xcluster-source
create table employees(id int primary key, name text);
(At target)
kubectl exec -it -n <target_universe_namespace> -t <target_universe_master_leader> -c <target_universe_container> -- bash
/home/yugabyte/bin/ysqlsh -h <target_universe_yqlserver>
create table query
For Example:
kubectl exec -it -n xcluster-target -t yb-master-2 -c yb-master -- bash
/home/yugabyte/bin/ysqlsh -h yb-tserver-1.yb-tservers.xcluster-target
create table employees(id int primary key, name text);
- Collect table UUIDs from the
Tablessection in the Admin UI (127.0.0.1:7000). - Setup replication from the source universe:
(At source)
kubectl exec -it -n <source_universe_namespace> -t <source_universe_master_leader> -c \
<source_universe_container> -- bash -c "/home/yugabyte/bin/yb-admin -master_addresses \
<target_universe_master_addresses> setup_universe_replication \
<source_universe_UUID>_<replication_stream_name> <source_universe_master_addresses> \
<comma_separated_table_ids>"
For Example:
kubectl exec -it -n xcluster-source -t yb-master-2 -c yb-master -- bash -c \
"/home/yugabyte/bin/yb-admin -master_addresses yb-master-2.yb-masters.xcluster-target.svc.cluster.local, \
yb-master-1.yb-masters.xcluster-target.svc.cluster.local,yb-master-0.yb-masters.xcluster-target.svc.cluster.local \
setup_universe_replication ac39666d-c183-45d3-945a-475452deac9f_xCluster_1 \
yb-master-2.yb-masters.xcluster-source.svc.cluster.local,yb-master-1.yb-masters.xcluster-source.svc.cluster.local, \
yb-master-0.yb-masters.xcluster-source.svc.cluster.local 00004000000030008000000000004001"
- Perform some DMLs on the source side and observe the replication at the target side.
(At source)
kubectl exec -it -n <source_universe_namespace> -t <source_universe_master_leader> -c <source_universe_container> -- bash
/home/yugabyte/bin/ysqlsh -h <source_universe_yqlserver>
insert query
select query
For Example:
kubectl exec -it -n xcluster-source -t yb-master-2 -c yb-master -- bash
/home/yugabyte/bin/ysqlsh -h yb-tserver-1.yb-tservers.xcluster-source
INSERT INTO employees VALUES(1, 'name');
SELECT * FROM employees;
(At target)
kubectl exec -it -n <target_universe_namespace> -t <target_universe_master_leader> -c <target_universe_container> -- bash
/home/yugabyte/bin/ysqlsh -h <target_universe_yqlserver>
select query
For Example:
kubectl exec -it -n xcluster-target -t yb-master-2 -c yb-master -- bash
/home/yugabyte/bin/ysqlsh -h yb-tserver-1.yb-tservers.xcluster-target
SELECT * FROM employees;
Bootstrapping a sink cluster
These instructions detail setting up xCluster for the following purposes:
- Setting up replication on a table that has existing data.
- Catching up an existing stream where the target has fallen too far behind.
Note
In order to ensure that the WALs are still available, the steps below need to be performed within the cdc_wal_retention_time_secs gflag window. If the process is going to take more time than the cdc_wal_retention_time_secs, you have to set cdc_wal_retention_time_secs flag to a higher value.-
First, we need to create a checkpoint on the source side for all the tables we want to replicate:
./bin/yb-admin -master_addresses <source_universe_master_addresses> \ bootstrap_cdc_producer <comma_separated_source_universe_table_ids>For Example:
./bin/yb-admin -master_addresses 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \ bootstrap_cdc_producer 000033e1000030008000000000004000,000033e1000030008000000000004003,000033e1000030008000000000004006This command returns a list of bootstrap_ids, one per table id as below:
table id: 000033e1000030008000000000004000, CDC bootstrap id: fb156717174941008e54fa958e613c10 table id: 000033e1000030008000000000004003, CDC bootstrap id: a2a46f5cbf8446a3a5099b5ceeaac28b table id: 000033e1000030008000000000004006, CDC bootstrap id: c967967523eb4e03bcc201bb464e0679 -
Take the backup of the tables on the source universe and restore at target universe. Backup-Restore
-
Then, set up the replication stream, using the bootstrap_ids generated in step 1
Note
It is important that the bootstrap_ids are in the same order as their corresponding table_ids!./bin/yb-admin -master_addresses <target_universe_master_addresses> setup_universe_replication \
<source_universe_uuid>_<replication_stream_name> <source_universe_master_addresses> \
<comma_separated_source_universe_table_ids> <comma_separated_bootstrap_ids>
For Example:
./bin/yb-admin-master_addresses 127.0.0.11:7100,127.0.0.12:7100,127.0.0.13:7100 setup_universe_replication \
00000000-1111-2222-3333-444444444444_xCluster1 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \
000033e1000030008000000000004000,000033e1000030008000000000004003,000033e1000030008000000000004006 \
fb156717174941008e54fa958e613c10,a2a46f5cbf8446a3a5099b5ceeaac28b,c967967523eb4e03bcc201bb464e0679
Schema migration
This section describs how to execute DDL operations, after replication has been already configured for some tables.
Stopping user writes
Some use cases can afford to temporarily stop incoming user writes. For such cases, the typical runbook would be:
- Stop any new incoming user writes.
- Wait for all changes to get replicated to the sink cluster. This can be observed by replication lag dropping to 0.
- Apply the DDL changes on both sides.
- Alter replication for any newly created tables, eg: after having used CREATE TABLE / CREATE INDEX.
- Resume user writes.
Using backup and restore
In the event you cannot stop incoming user traffic, then the recommended approach would be to apply DDLs on the source cluster and use bootstrapping a sink cluster flow above. A more detailed runbook would be as follows:
- Stop replication, in advance of DDL changes.
- Apply all your DDL changes to the source cluster.
- Take a backup of the source cluster, of all the relevant tables that you intend to replicate changes for.
- Make sure to use the bootstrapping a sink cluster flow, as described above.
- Restore this backup on the sink cluster.
- Setup replication again, for all of the relevant tables.
- Make sure to pass in the
bootstrap_ids, as described above.
- Make sure to pass in the