MongoDB
Even though it has improved its transactional capabilities over the last few years, MongoDB is still architecturally not a good fit for transactional applications with strict guarantees on low latency and high throughput. Using transactions in MongoDB today essentially means giving up on high performance and horizontal scalability. Yugabyte believe this is a compromise fast-growing online services should not be forced to make. As shown in the table below, we architected YugabyteDB to simultaneously deliver transactional guarantees, high performance and linear scalability. A 3-node YugabyteDB cluster supports both single-shard and multi-shard transactions and seamlessly scales out on-demand (in single region as well as across multiple regions) to increase write throughput without compromising low latency reads.
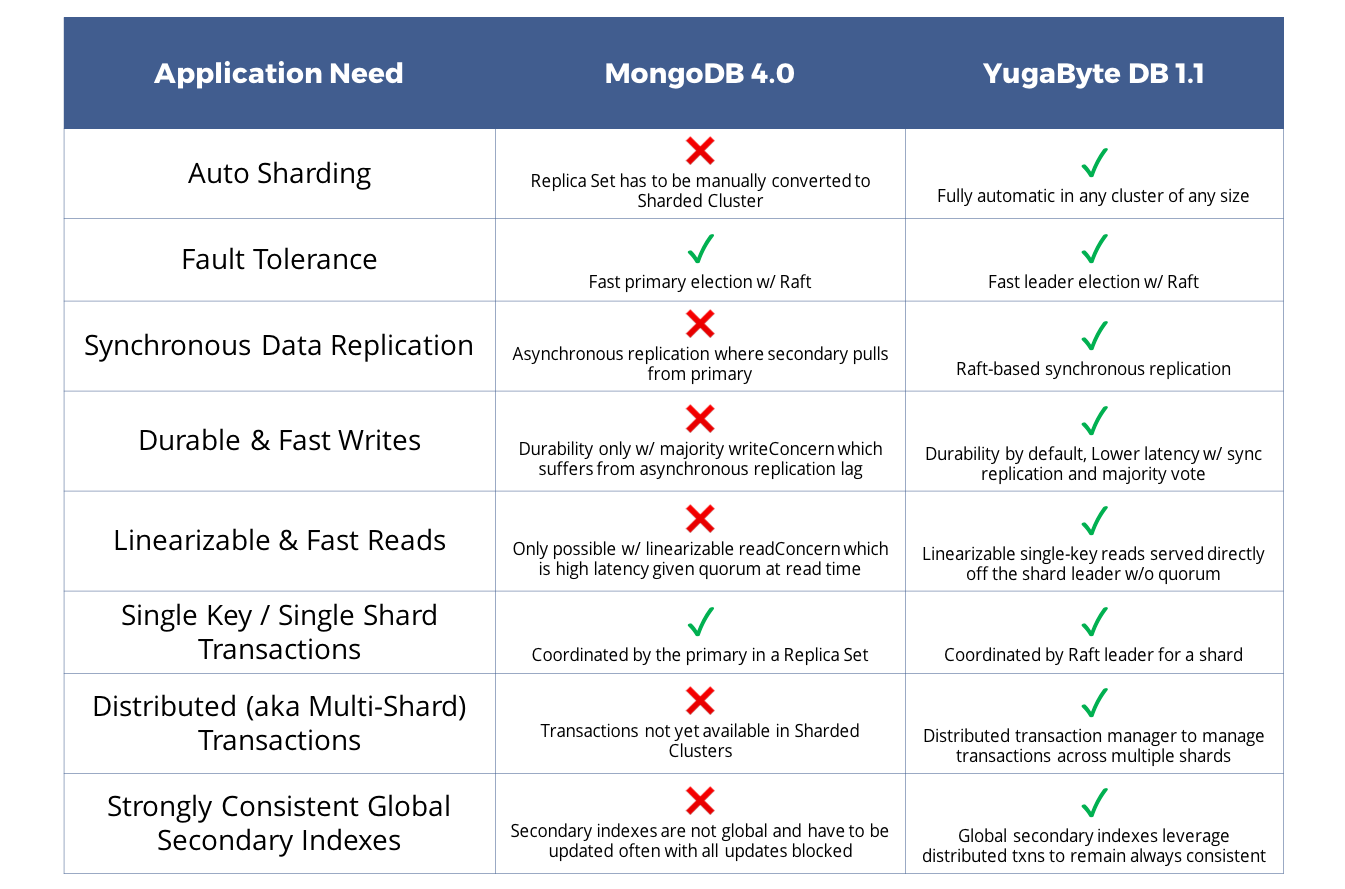
Following are the key areas of difference between YugabyteDB 1.1 and MongoDB 4.0.
Data modeling
MongoDB is a document-oriented database that only supports document data modeling. On the other hand, YugabyteDB is a multi-model and multi-API database that supports multiple different types of data modeling including document data (with the native JSON data type support in the Cassandra-compatible YCQL API). Additionally, YugabyteDB supports key-value (with the Redis-compatible YEDIS API) and relational (with the PostgreSQL-compatible YSQL API) data modeling.
Automatic sharding
Sharding is not automatic in MongoDB since a Replica Set has to be manually converted to Sharded Cluster. On the other hand, YugabyteDB automatically shards data in any cluster of any size.
Fault tolerance
Fault-tolerance for a given shard is similar in both systems since both rely on Raft consensus protocol for fast primary/leader election.
Synchronous data replication
While primary election is Raft-based in MongoDB, actual data replication is not. Data replication is asynchronous where secondary pulls from primary. Both leader election and data replication are based on Raft distributed consensus.
Durable and fast writes
Durability can be achieved in MongoDB only w/ majority writeConcern which suffers from asynchronous replication lag. On the other hand, durability is by default in YugabyteDB since the write path is based on Raft's synchronous data replication and majority consensus. Synchronous replication is typically of lower latency than the completely asynchronous approach of MongoDB.
Linearizable and fast reads
Linearizable single-key reads are only possible w/ linearizable readConcern which is high latency given quorum at read time. On the other hand, linearizable reads served directly off the shard leader w/o quorum in YugabyteDB making it 3x faster than MongoDB both in terms of latency and throughput.
Single key and single shard transactions
Both databases support single-key and single-shard transactions. In MongoDB, the transaction is coordinated by the primary in a Replica Set. In YugabyteDB, the transaction is coordinated by Raft leader for a shard (similar to Google Spanner).
Distributed (aka multi-shard) transactions
Distributed transactions not yet available in MongoDB Sharded Clusters. On the other hand, YugabyteDB has full support for distributed transactions based on a distributed transaction manager that manages transactions across multiple shards (similar in architecture to that of Google Spanner).
Strongly consistent global secondary indexes
MongoDB secondary indexes are not global and have to be updated often with all updates blocked for special cases such as unique secondary indexes. On the other hand, global secondary indexes leverage distributed txns to remain always consistent without any need for out-of-band index re-builds.
High data density
MongoDB's WiredTiger storage engine runs only the B-Tree mode even though WiredTiger itself has support for the Log Structured Merge (LSM) mode. B-Tree engines are good for fast searches while LSM engines are suitable for storing large amounts of data on modern SSDs. While LSM engines can be optimzied to increase read informance, optimizing write performance in a B-Tree engine is not easy. This choice of B-Tree engine tends to make MongoDB suitable only for small workloads where each ReplicaSet primary node is a terabyte or less. However, YugabyteDB can store multi-terabytes of data per node and elastically scale as needed.
Relevant blog posts
A few blog posts that highlight how YugabyteDB differs from MongoDB are below.
-
Are MongoDB’s ACID Transactions Ready for High Performance Applications?
-
Overcoming MongoDB Sharding and Replication Limitations with YugabyteDB
-
YugabyteDB 1.1 New Feature: Document Data Modeling with the JSON Data Type
-
DynamoDB vs MongoDB vs Cassandra for Fast Growing Geo-Distributed Apps
-
Benchmarking an 18 Terabyte YugabyteDB Cluster with High Density Data Nodes