Scaling YSQL queries
There are a number of well-known experiments where eventually-consistent NoSQL databases were scaled out to perform millions of inserts and queries. Here, you do the same using YSQL, the Yugabyte SQL API that is PostgreSQL-compatible, strongly-consistent, and supports distributed SQL. We created a 100-node YugabyteDB cluster, ran single-row INSERT and SELECT workloads with high concurrency – each for an hour and measured the sustained performance (throughput and latency). This topic details the results of this experiment as well as highlights the key aspects of the YugabyteDB architecture that makes it fit for such high-volume ingest workloads. Although this topic describes the results of benchmark tests performed by Yugabyte, you can follow the steps below to perform your own benchmarks on the scalability of queries in your YugabyteDB clusters.
Database cluster setup
While YugabyteDB can be deployed across multiple availability zones or regions, this benchmark focused on the aggregate performance of a 100-node cluster. Therefore, all 100 nodes were deployed on the Amazon Web Services (AWS) cloud in the US West (Oregon) region (us-west-2) and in a single availability zone (us-west-2a). Each of the instances were of type c5.4xlarge (16 vCPUs). This information is summarized below.
- Cluster name: MillionOps
- Cloud: Amazon Web Services
- Region: Oregon (
us-west-2) - Zone:
us-west-2a - Number of nodes: 100
- Instance type:
c5.4xlarge(16 vCPUs) - Disk on each node: 1TB EBS SSD (
gp2) - Replication Factor (RF):
3 - Consistency level: Strong consistency for both writes and reads
Benchmark setup
The benchmark application was an open-source Java program. The application’s database workload simply does multi-threaded, single-row INSERT and SELECT statements against a table that has a key and a value column. The size of each row was 64 bytes. The insert and select benchmarks were run for one hour each in order to measure the sustained throughput and latency.
This benchmark application was run on six instances of eight cores each. Note that we could not consolidate into a fewer number of more powerful instances since we were hitting the maximum network bandwidth on the network instances. Each of these benchmark instances were prepared as shown below.
Java 8 was installed using the following commands.
$ sudo apt update
$ sudo apt install default-jre
The YugabyteDB workload generator was downloaded on to these machines as shown below.
$ wget -P target https://github.com/yugabyte/yb-sample-apps/releases/download/1.3.9/yb-sample-apps.jar
This benchmark program can take a list of servers in the database cluster, and then perform random operations across these servers. In order to do this, we set up an environment variable with the list of comma-separated host:port entries of the 100 database servers as shown below.
$ export YSQL_NODES=node-1-ip-addr:5433,node-2-ip-addr:5433,...
Benchmarking the INSERT workload
The first step was to run an INSERT benchmark (using the SqlInserts workload generator) on this 100-node cluster. The following command was run on each of the benchmark instances.
java -jar ~/yb-sample-apps-no-table-drop.jar \
--workload SqlInserts \
--nodes $YSQL_NODES \
--num_unique_keys 5000000000 \
--num_threads_write 400 \
--num_threads_read 0 \
--uuid 00000000-0000-0000-0000-00000000000n
java -jar ~/yb-sample-apps-no-table-drop.jar \
--workload SqlInserts \
--nodes $YSQL_NODES \
--num_unique_keys 5000000000 \
--num_threads_write 400 \
--num_threads_read 0 \
--uuid 00000000-0000-0000-0000-00000000000n
The table on which the benchmark was run had the following simple schema.
CREATE TABLE table_name (k varchar PRIMARY KEY, v varchar);
This workload performed a number of INSERTs using prepared statements, as shown below.
INSERT INTO table_name (k, v) VALUES (?, ?);
Note a few points about the benchmark setup.
-
Each benchmark program writes unique set of rows. The
uuidparameter forms a prefix of the row key. It is set differently (by varying the value ofnfrom1to6) on each benchmark instance to ensure it writes separate keys. -
A total of 30 billion unique rows will be inserted upon completion. Each benchmark program proceeds to write out 5 billion keys, and there are six such programs running in parallel.
-
There are 2400 concurrent clients performing inserts. Each benchmark program uses 400 write threads, and there are six such programs running concurrently.
A screenshot of the write throughput on this cluster while the benchmark was in progress is shown below. The write throughput was 1.26 million inserts per second.
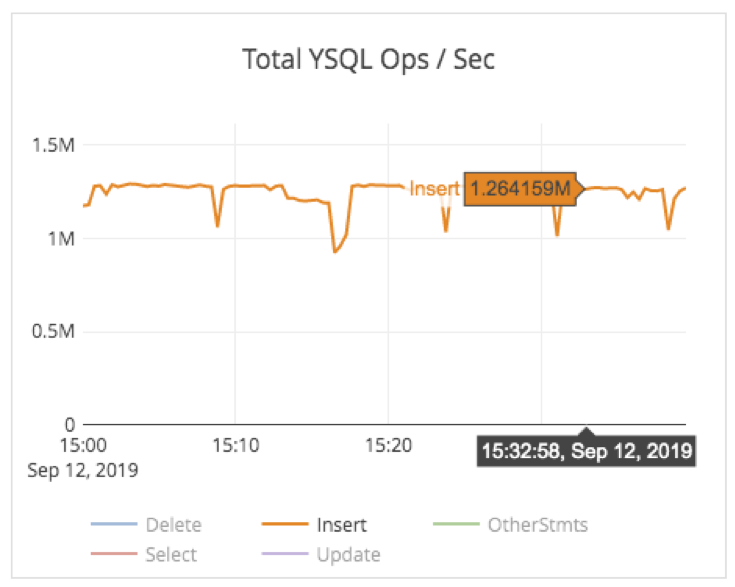
The corresponding average insert latency across all the 100 nodes was 1.66 milliseconds (ms), as shown below. Note that each insert is replicated three-ways to make the cluster fault tolerant.
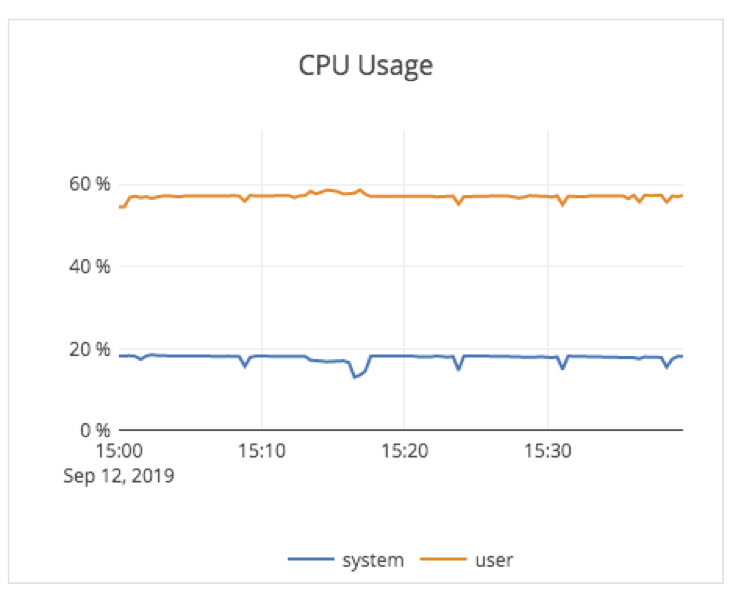
The average CPU usage across the nodes in the cluster was about 78%, as shown in the graph below.
Benchmarking the SELECT workload
The following command was run for the SELECT workload.
java -jar ~/yb-sample-apps-no-table-drop.jar \
--workload SqlInserts \
--nodes $YSQL_NODES \
--max_written_key 500000000 \
--num_writes 0 \
--num_reads 50000000000 \
--num_threads_write 0 \
--num_threads_read 400 \
--read_only \
--uuid 00000000-0000-0000-0000-00000000000n
The SELECT workload looks up random rows on the table that the INSERT workload (described in the previous section) populated. Each SELECT query is performed using prepared statements, as shown below.
SELECT * FROM table_name WHERE k=?;
There are 2,400 concurrent clients issuing SELECT statements. Each benchmark program uses 400 threads, and there are six programs running in parallel. Each read operation randomly selects one row from a total of 3 billion rows. Each benchmark program randomly queries one row from a total of 500 million rows, and there are six concurrent programs.
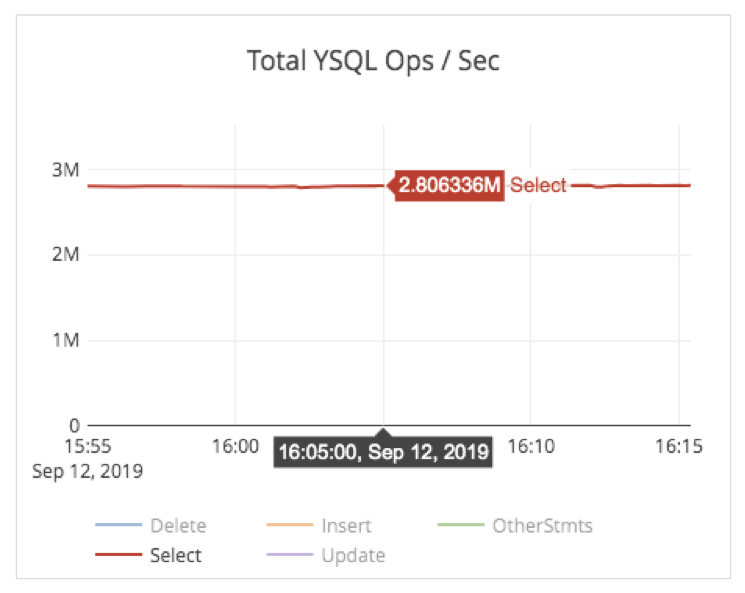
The read throughput on this cluster while the benchmark was in progress is shown below. The read throughput was 2.8 million selects per second. YugabyteDB reads are strongly consistent by default and that is the setting used for this benchmark. Additional throughput can be achieved by simply allowing timeline-consistent reads from follower replicas (see Architecture for horizontal write scaling below).
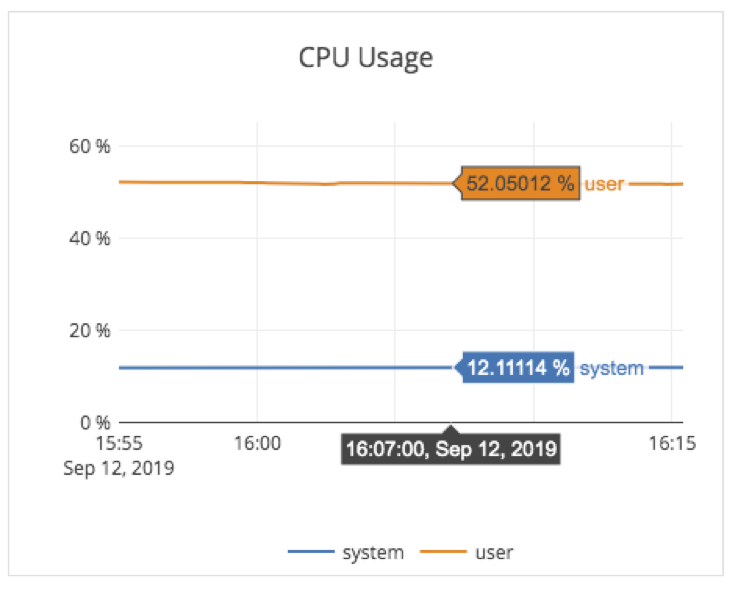
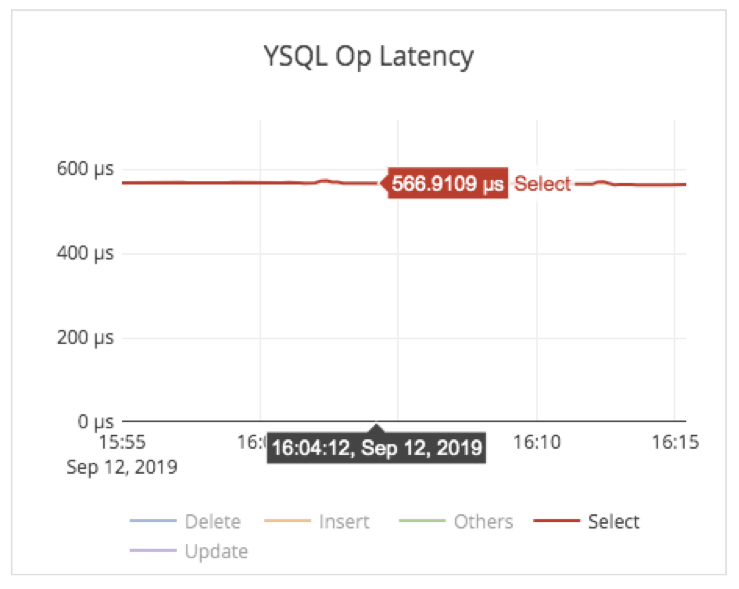
The corresponding average select latency across all the 100 nodes was 0.56ms, as shown below.
The average CPU usage across the nodes in the cluster was about 64%, as shown in the graph below.
Architecture for horizontal write scaling
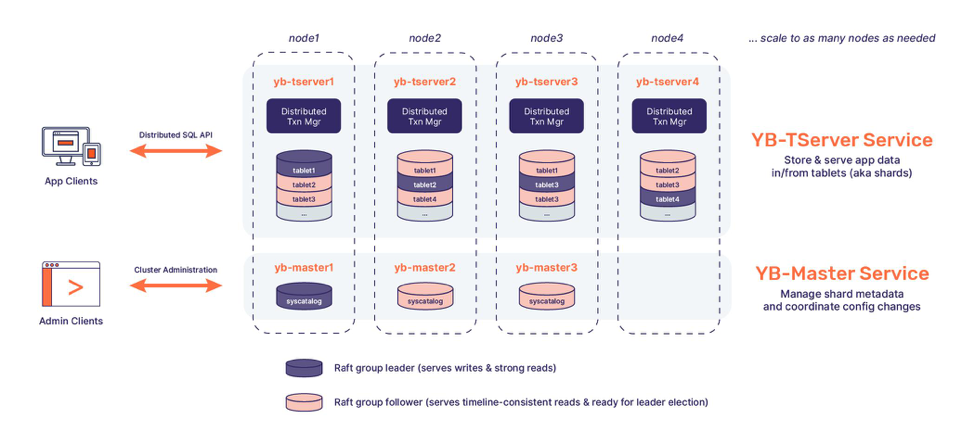
The architecture of a YugabyteDB cluster is shown in the figure below. The YB-TServer service is responsible for managing the data in the cluster while the YB-Master service manages the system configuration of the cluster. YB-TServer automatically shards every table into a number of shards (aka tablets). Given the replication factor (RF) of 3 for the cluster, each tablet is represented as a Raft group of three replicas with one replica considered the leader and other two replicas considered as followers. In a 100-node cluster, each of these three replicas are automatically stored on exactly three (out of 100) different nodes where each node can be thought of as representing an independent fault domain. YB-Master automatically balances the total number of leader and follower replicas on all the nodes so that no single node becomes a bottleneck and every node contributes its fair share to incoming client requests. The end result is strong write consistency (by ensuring writes are committed at a majority of replicas) and tunable read consistency (by serving strong reads from leaders and timeline-consistent reads from followers), irrespective of the number of nodes in the cluster.
To those new to the Raft consensus protocol, the simplest explanation is that it is a protocol with which a cluster of nodes can agree on values. It is arguably the most popular distributed consensus protocol in use today. Business-critical cloud-native systems like etcd (the configuration store for Kubernetes) and consul (HashiCorp’s popular service discovery solution) are built on Raft as a foundation. YugabyteDB uses Raft for both leader election as well as the actual data replication. The benefits of YugabyteDB’s use of Raft including rapid scaling (with fully-automatic rebalancing) are highlighted in the Yugabyte blog on “How Does the Raft Consensus-Based Replication Protocol Work in YugabyteDB?”. Raft is tightly integrated with a high-performance document store (extended from RocksDB) to deliver on the promise of massive write scalability combined with strong consistency and low latency.
Next steps
You can visit the YugabyteDB workload generator GitHub repository to try out more experiments on your own local setups. After you set up a cluster and test your favorite application, share your feedback and suggestions with other users on the YugabyteDB Community Slack.