Persistence
Once data is replicated using Raft across a majority of the YugabyteDB tablet-peers, it is applied to each tablet peer’s local DocDB document storage layer.
Storage Model
This storage layer is a persistent key to object/document store. The storage model is shown in the figure below:
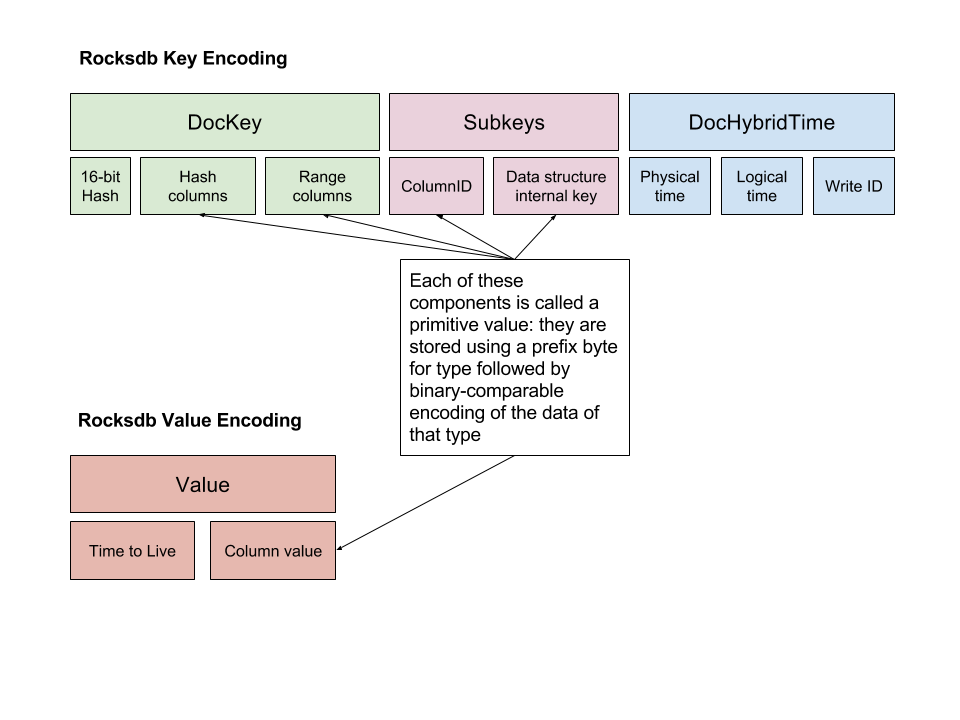
The keys and the corresponding document values are described below.
DocDB key
The keys in DocDB document model are compound keys consisting of one or more hash organized components, followed by zero or more ordered (range) components. These components are stored in their data type specific sort order; both ascending and descending sort order is supported for each ordered component of the key.
DocDB value
The values in DocDB document data model can be:
- primitive types: such as int32, int64, double, text, timestamp, etc.
- non-primitive types (sorted maps): These objects map scalar keys to values, which could be either scalar or sorted maps as well.
This model allows multiple levels of nesting, and corresponds to a JSON-like format. Other data structures like lists, sorted sets etc. are implemented using DocDB’s object type with special key encodings. In DocDB, hybrid timestamps of each update are recorded carefully, so that it is possible to recover the state of any document at some point in the past. Overwritten or deleted versions of data are garbage-collected as soon as there are no transactions reading at a snapshot at which the old value would be visible.
Encoding documents
The documents are stored using a key-value store based on RocksDB, which is typeless. The documents are converted to multiple key-value pairs along with timestamps. Because documents are spread across many different key-values, it’s possible to partially modify them cheaply.
For example, consider the following document stored in DocDB:
DocumentKey1 = {
SubKey1 = {
SubKey2 = Value1
SubKey3 = Value2
},
SubKey4 = Value3
}
Keys stored in RocksDB consist of a number of components, where the first component is a "document key", followed by a few scalar components, and finally followed by a MVCC timestamp (sorted in reverse order). Each component in the DocumentKey, SubKey, and Value, are PrimitiveValues, which are just (type, value) pairs, which can be encoded to and decoded from strings. When encoding primitive values in keys, a binary-comparable encoding is used for the value, so that sort order of the encoding is the same as the sort order of the value.
Updates and deletes
Assume that the example document above was written at time T10 entirely. Internally the above example’s document is stored using 5 RocksDB key value pairs:
DocumentKey1, T10 -> {} // This is an init marker
DocumentKey1, SubKey1, T10 -> {}
DocumentKey1, SubKey1, SubKey2, T10 -> Value1
DocumentKey1, SubKey1, SubKey3, T10 -> Value2
DocumentKey1, SubKey4, T10 -> Value3
Deletions of Documents and SubDocuments are performed by writing a single Tombstone marker at the corresponding value. During compaction, overwritten or deleted values are cleaned up to reclaim space.
Mapping SQL rows to DocDB
For YSQL (and YCQL) tables, every row is a document in DocDB.
Primary key columns
The document key contains the full primary key with column values organized in the following order:
- A 16-bit hash of the hash column values is stored first
- The hash column(s) are stored next
- The clustering (range) column(s) are stored next
Each data type supported in YSQL (or YCQL) is represented by a unique byte. The type prefix is also present in the primary key’s hash or range components
Non-Primary key columns
The non-primary key columns correspond to subdocuments within the document. The subdocument key corresponds to the column ID. There’s a unique byte for each data type we support in YSQL (or YCQL). The values are prefixed with the corresponding byte. If a column is a non-primitive type (such as a map or set), the corresponding subdocument is an Object.
We use a binary-comparable encoding to translate the value for each YCQL type to strings that go to the KV-Store.
Data expiration in YCQL
In YCQL there are two types of TTL, the table TTL and column level TTL. The column TTLs are stored with the value using the same encoding as Redis. The Table TTL is not stored in DocDB (it is stored in master’s syscatalog as part of the table’s schema). If no TTL is present at the column’s value, the table TTL acts as the default value.
Furthermore, YCQL has a distinction between rows created using Insert vs Update. We keep track of this difference (and row level TTLs) using a "liveness column", a special system column invisible to the user. It is added for inserts, but not updates: making sure the row is present even if all non-primary key columns are deleted only in the case of inserts.
YCQL - Collection type example
Consider the following YCQL table schema:
CREATE TABLE msgs (user_id text,
msg_id int,
msg text,
msg_props map<text, text>,
PRIMARY KEY ((user_id), msg_id));
Insert a row
T1: INSERT INTO msgs (user_id, msg_id, msg, msg_props)
VALUES ('user1', 10, 'msg1', {'from' : 'a@b.com', 'subject' : 'hello'});
The entries in DocDB at this point will look like the following:
(hash1, 'user1', 10), liveness_column_id, T1 -> [NULL]
(hash1, 'user1', 10), msg_column_id, T1 -> 'msg1'
(hash1, 'user1', 10), msg_props_column_id, 'from', T1 -> 'a@b.com'
(hash1, 'user1', 10), msg_props_column_id, 'subject', T1 -> 'hello'
Update subset of columns
T2: UPDATE msgs
SET msg_props = msg_props + {'read_status' : 'true'}
WHERE user_id = 'user1', msg_id = 10
The entries in DocDB at this point will look like the following:
(hash1, 'user1', 10), liveness_column_id, T1 -> [NULL]
(hash1, 'user1', 10), msg_column_id, T1 -> 'msg1'
(hash1, 'user1', 10), msg_props_column_id, 'from', T1 -> 'a@b.com'
(hash1, 'user1', 10), msg_props_column_id, 'read_status', T2 -> 'true'
(hash1, 'user1', 10), msg_props_column_id, 'subject', T1 -> 'hello'
Update entire row
T3: INSERT INTO msgs (user_id, msg_id, msg, msg_props)
VALUES (‘user1’, 20, 'msg2', {'from' : 'c@d.com', 'subject' : 'bar'});
The entries in DocDB at this point will look like the following:
(hash1, 'user1', 10), liveness_column_id, T1 -> [NULL]
(hash1, 'user1', 10), msg_column_id, T1 -> 'msg1'
(hash1, 'user1', 10), msg_props_column_id, 'from', T1 -> 'a@b.com'
(hash1, 'user1', 10), msg_props_column_id, 'read_status', T2 -> 'true'
(hash1, 'user1', 10), msg_props_column_id, 'subject', T1 -> 'hello'
(hash1, 'user1', 20), liveness_column_id, T3 -> [NULL]
(hash1, 'user1', 20), msg_column_id, T3 -> 'msg2'
(hash1, 'user1', 20), msg_props_column_id, 'from', T3 -> 'c@d.com'
(hash1, 'user1', 20), msg_props_column_id, 'subject', T3 -> 'bar'
Delete a row
Delete a single column from a row.
T4: DELETE msg_props
FROM msgs
WHERE user_id = 'user1'
AND msg_id = 10;
Even though, in the example above, the column being deleted is a non-primitive column (a map), this operation only involves adding a delete marker at the correct level, and does not incur any read overhead. The logical layout in DocDB at this point is shown below.
(hash1, 'user1', 10), liveness_column_id, T1 -> [NULL]
(hash1, 'user1', 10), msg_column_id, T1 -> 'msg1'
(hash1, 'user1', 10), msg_props_column_id, T4 -> [DELETE]
(hash1, 'user1', 10), msg_props_column_id, 'from', T1 -> 'a@b.com'
(hash1, 'user1', 10), msg_props_column_id, 'read_status', T2 -> 'true'
(hash1, 'user1', 10), msg_props_column_id, 'subject', T1 -> 'hello'
(hash1, 'user1', 20), liveness_column_id, T3 -> [NULL]
(hash1, 'user1', 20), msg_column_id, T3 -> 'msg2'
(hash1, 'user1', 20), msg_props_column_id, 'from', T3 -> 'c@d.com'
(hash1, 'user1', 20), msg_props_column_id, 'subject', T3 -> 'bar'
Note: The KVs that are displayed in “strike-through” font are logically deleted.
Note: The above is not the physical layout per se, as the writes happen in a log-structured manner. When compactions happen, the space for the KVs corresponding to the deleted columns is reclaimed, as shown below.
(hash1, 'user1', 10), liveness_column_id, T1 -> [NULL]
(hash1, 'user1', 10), msg_column_id, T1 -> 'msg1'
(hash1, 'user1', 20), liveness_column_id, T3 -> [NULL]
(hash1, 'user1', 20), msg_column_id, T3 -> 'msg2'
(hash1, 'user1', 20), msg_props_column_id, 'from', T3 -> 'c@d.com'
(hash1, 'user1', 20), msg_props_column_id, 'subject', T3 -> 'bar'
T5: DELETE FROM msgs // Delete entire row corresponding to msg_id 10
WHERE user_id = 'user1'
AND msg_id = 10;
(hash1, 'user1', 10), T5 -> [DELETE]
(hash1, 'user1', 10), liveness_column_id, T1 -> [NULL]
(hash1, 'user1', 10), msg_column_id, T1 -> 'msg1'
(hash1, 'user1', 20), liveness_column_id, T3 -> [NULL]
(hash1, 'user1', 20), msg_column_id, T3 -> 'msg2'
(hash1, 'user1', 20), msg_props_column_id, 'from', T3 -> 'c@d.com'
(hash1, 'user1', 20), msg_props_column_id, 'subject', T3 -> 'bar'
YCQL - Time-To-Live (TTL) example
Table Level TTL: YCQL allows the TTL property to be specified at the table level. In this case, we do not store the TTL on a per KV basis in RocksDB; but the TTL is implicitly enforced on reads as well as during compactions (to reclaim space).
Row and column level TTL: YCQL allows the TTL property to be specified at the level of each INSERT/UPDATE operation. In such cases, the TTL is stored as part of the RocksDB value.
Below, we will look at how the row-level TTL is achieved in detail.
CREATE TABLE page_views (page_id text,
views int,
category text,
PRIMARY KEY ((page_id)));
Insert row with TTL
T1: INSERT INTO page_views (page_id, views)
VALUES ('abc.com', 10)
USING TTL 86400
// The entries in DocDB will look like the following
(hash1, 'abc.com'), liveness_column_id, T1 -> (TTL = 86400) [NULL]
(hash1, 'abc.com'), views_column_id, T1 -> (TTL = 86400) 10
Update row with TTL
T2: UPDATE page_views
USING TTL 3600
SET category = 'news'
WHERE page_id = 'abc.com';
// The entries in DocDB will look like the following
(hash1, 'abc.com'), liveness_column_id, T1 -> (TTL = 86400) [NULL]
(hash1, 'abc.com'), views_column_id, T1 -> (TTL = 86400) 10
(hash1, 'abc.com'), category_column_id, T2 -> (TTL = 3600) 'news'