Tablet splitting
Overview
Tablet splitting is the resharding of data in the cluster by presplitting tables before data is added or by changing the number of tablets at runtime. In the sections below, three mechanisms for tablet splitting in YugabyteDB clusters are explained.
Here are some of the scenarios where tablet splitting is useful.
Range scans
In use cases that scan a range of data, the data is stored in the natural sort order (also known as range-sharding). In these usage patterns, it is often impossible to predict a good split boundary ahead of time. For example:
CREATE TABLE census_stats (
age INTEGER,
user_id INTEGER,
...
);
In the example above, picking a good split point ahead of time is difficult. The database cannot infer the range of values for age (typically in the 1 to 100 range) in the table. And the distribution of rows in the table (that is, how many user_id rows will be inserted for each value of age to make an evenly distributed data split) is impossible to predict.
Low-cardinality primary keys
In use cases with a low-cardinality of the primary keys (or the secondary index), hashing is not effective. For example, if a table where the primary key (or index) is the column gender, with only two values (Male or Female), hash sharding would not be effective. Using the entire cluster of machines to maximize serving throughput, however, is important.
Small tables that become very large
Some tables start off small, with only a few shards. If these tables grow very large, however, then nodes will be continuosly added to the cluster. Scenarios are possible where the number of nodes exceeds the number of tablets. To effectively rebalance the cluster, tablet splitting is required.
Approaches to tablet splitting
DocDB allows data resharding by splitting tablets using the following three mechanisms:
-
Presplitting tablets: All tables created in DocDB can be split into the desired number of tablets at creation time.
-
Manual tablet splitting: The tablets in a running cluster can be split manually at runtime by the user.
-
Automatic tablet splitting: The tablets in a running cluster are automatically split according to some policy by the database.
The following sections give details on how to split tablets using these three approaches.
Presplitting tablets
At creation time, you can presplit a table into the desired number of tablets. YugabyteDB supports presplitting tablets for both range-sharded and hash-sharded YSQL tables and hash-sharded YCQL tables. The number of tablets can be specified in one of two ways:
-
Desired number of tablets: In this case, the table is created with the desired number of tablets.
-
Desired number of tablets per node: In this case, the total number of tablets the table is split into is computed as follows:
num_tablets_in_table = num_tablets_per_node * num_nodes_at_table_creation_time
Note
In order to presplit a table into a desired number of tablets, you need the start key and end key for each tablet. This makes presplitting slightly different for hash-sharded and range-sharded tables.Hash-sharded tables
Because hash sharding works by applying a hash function on all, or a subset of, the primary key columns, the byte space of the hash sharded keys is known ahead of time. For example, if you use a 2-byte hash, the byte space would be [0x0000, 0xFFFF].
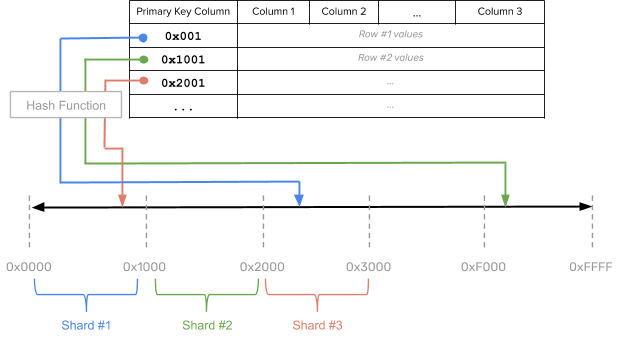
In the diagram above, the YSQL table is split into 16 shards. This can be achieved by using the SPLIT INTO 16 TABLETS clause as a part of the CREATE TABLE statement, as shown below.
CREATE TABLE customers (
customer_id bpchar NOT NULL,
company_name character varying(40) NOT NULL,
contact_name character varying(30),
contact_title character varying(30),
address character varying(60),
city character varying(15),
region character varying(15),
postal_code character varying(10),
country character varying(15),
phone character varying(24),
fax character varying(24),
PRIMARY KEY (customer_id HASH)
) SPLIT INTO 16 TABLETS;
For YSQL API support, see:
- CREATE TABLE ... SPLIT INTO and the example, Create a table specifying the number of tablets.
- CREATE INDEX ... SPLIT INTO and the example, Create an index specifying the number of tablets.
For YCQL API support, see:
- CREATE TABLE ... WITH tablets and the example, Create a table specifying the number of tablets.
Range-sharded tables
In range-sharded YSQL tables, the start and end key for each tablet is not immediately known since this depends on the column type and the intended usage. For example, if the primary key is a percentage NUMBER column where the range of values is in the [0, 100] range, presplitting on the entire NUMBER space would not be effective.
For this reason, in order to presplit range-sharded tables, you must explicitly specify the split points. These explicit split points can be specified as shown below.
CREATE TABLE customers (
customer_id bpchar NOT NULL,
company_name character varying(40) NOT NULL,
contact_name character varying(30),
contact_title character varying(30),
address character varying(60),
city character varying(15),
region character varying(15),
postal_code character varying(10),
country character varying(15),
phone character varying(24),
fax character varying(24),
PRIMARY KEY (customer_id ASC)
) SPLIT AT VALUES ((1000), (2000), (3000), ... );
For YSQL API details, see:
- CREATE TABLE ... SPLIT AT VALUES for use with range-sharded tables.
Manual tablet splitting
Imagine there is a table with pre-existing data spread across a certain number of tablets. It is possible to split some or all of the tablets in this table manually. This is shown in the example below.
Create a sample YSQL table
-
Create a three-node local cluster.
bin/yb-ctl --rf=3 create --ysql_num_shards_per_tserver=1 -
Create a sample table and insert some data.
CREATE TABLE t (k VARCHAR, v TEXT, PRIMARY KEY (k)) SPLIT INTO 1 TABLETS; -
Insert some sample data (100K rows) into this table.
INSERT INTO t (k, v) SELECT i::text, left(md5(random()::text), 4) FROM generate_series(1, 100000) s(i);SELECT count(*) FROM t;count -------- 100000 (1 row)
Verify the table has one tablet
In order to verify that the table t has only one tablet, list all the tablets for table t using the following yb-admin list_tablets command.
bin/yb-admin --master_addresses 127.0.0.1:7100 list_tablets ysql.yugabyte t
This produces the following output. Note the tablet UUID for later use, to split this tablet.
Tablet UUID Range Leader
9991368c4b85456988303cd65a3c6503 key_start: "" key_end: "" 127.0.0.1:9100
Manually split the tablet
The tablet of this table can be manually split into two tablets by running the following yb-admin split_tablet command.
bin/yb-admin \
--master_addresses 127.0.0.1:7100,127.0.0.2:7100,127.0.0.3:7100 \
split_tablet 9991368c4b85456988303cd65a3c6503
After the split, you see two tablets for the table t.
bin/yb-admin --master_addresses 127.0.0.1:7100 list_tablets ysql.yugabyte t
Tablet UUID Range Leader
20998f68c3fa4d299e8af7c04410e230 key_start: "" key_end: "\177\377" 127.0.0.1:9100
a89ecb84ad1b488b893b6e7762a6ca2a key_start: "\177\377" key_end: "" 127.0.0.3:9100
Important
- The original tablet
9991368c4b85456988303cd65a3c6503no longer exists and has been replaced with two new tablets. - The tablet leaders are now spread across two nodes in order to evenly balance the tablets for the table across the nodes of the cluster.
Automatic tablet splitting
Automatic tablet splitting enables resharding of data in a cluster automatically while online, and transparently to users, when a specified size threshold has been reached.
For details on the architecture design, see Automatic Re-sharding of Data with Tablet Splitting.
Enable automatic tablet splitting
To enable automatic tablet splitting, use the yb-master --enable_automatic_tablet_splitting command, and specify the associated flags to configure when tablets should split.
Tablet splitting happens in three phases, determined by the shard count per node. As the shard count increases, the threshold size for splitting a tablet also increases:
-
In the low phase, each node has fewer than
tablet_split_low_phase_shard_count_per_nodeshards. In this phase, YugabyteDB splits tablets larger thantablet_split_low_phase_size_threshold_bytes. -
In the high phase, each node has fewer than
tablet_split_high_phase_shard_count_per_nodeshards. In this phase, YugabyteDB splits tablets larger thantablet_split_high_phase_size_threshold_bytes. -
Once the shard count exceeds the high phase count, YugabyteDB splits tablets larger than [
tablet_force_split_threshold_bytes].
When automatic tablet splitting is enabled, newly-created tables have one shard per tserver by default.
Example: YCSB workload with automatic tablet splitting
In the following example, a three-node cluster is created and uses a YCSB workload to demonstrate the use of automatic tablet splitting in a YSQL database. For details on using YCSB with YugabyteDB, see the YCSB section in the Benchmark guide.
-
Create a three-node cluster.
./bin/yb-ctl --rf=3 create --master_flags "enable_automatic_tablet_splitting=true,tablet_split_low_phase_size_threshold_bytes=30000000" --tserver_flags "memstore_size_mb=10" -
Create a table for workload.
./bin/ysqlsh -c "CREATE DATABASE ycsb;" ./bin/ysqlsh -d ycsb -c "CREATE TABLE usertable ( YCSB_KEY TEXT, FIELD0 TEXT, FIELD1 TEXT, FIELD2 TEXT, FIELD3 TEXT, FIELD4 TEXT, FIELD5 TEXT, FIELD6 TEXT, FIELD7 TEXT, FIELD8 TEXT, FIELD9 TEXT, PRIMARY KEY (YCSB_KEY ASC));" -
Create the properties file for YCSB at
~/code/YCSB/db-local.propertiesand add the following content.db.driver=org.postgresql.Driver db.url=jdbc:postgresql://127.0.0.1:5433/ycsb;jdbc:postgresql://127.0.0.2:5433/ycsb;jdbc:postgresql://127.0.0.3:5433/ycsb db.user=yugabyte db.passwd= core_workload_insertion_retry_limit=10 -
Start loading data for the workload.
~/code/YCSB/bin/ycsb load jdbc -s -P ~/code/YCSB/db-local.properties -P ~/code/YCSB/workloads/workloada -p recordcount=500000 -p operationcount=1000000 -p threadcount=4 -
Monitor the tablet splitting using the YugabyteDB web interfaces at
http://localhost:7000/tablet-serversandhttp://127.0.0.1:9000/tablets. -
Run the workload.
~/code/YCSB/bin/ycsb run jdbc -s -P ~/code/YCSB/db-local.properties -P ~/code/YCSB/workloads/workloada -p recordcount=500000 -p operationcount=1000000 -p threadcount=4 -
Get the list of tablets accessed during the run phase of the workload.
diff -C1 after-load.json after-run.json | grep tablet_id | sort | uniq -
The list of tablets accessed can be compared with
http://127.0.0.1:9000/tabletsto make sure no presplit tablets have been accessed.
Current limitations
Limitations
The following known limitations are planned to be resolved in upcoming releases:
- Colocated tables cannot be split. #4463
- Tablet splitting should be disabled during an index backfill. #6704
- Cross cluster replication currently does not work with tablet splitting. #5373
To follow the tablet splitting work-in-progress, see #1004.