Replication
DocDB automatically replicates data synchronously in order to survive failures while maintaining data consistency and avoiding operator intervention. It does so using the Raft distributed consensus protocol.
Overview
Fault domains
A fault domain comprises a group of nodes that are prone to correlated failures. Examples of fault domains are:
- Zones or racks
- Regions or datacenters
- Cloud providers
Data is typically replicated across fault domains to be resilient to the outage of all nodes in that fault domain.
Fault tolerance
The fault tolerance (FT) of a YugabyteDB universe is the maximum number of node failures it can survive while continuing to preserve correctness of data.
Replication factor
YugabyteDB replicates data across nodes (or fault domains) in order to tolerate faults. The replication factor (RF) is the number of copies of data in a YugabyteDB universe. FT and RF are correlated. To achieve a FT of k nodes, the universe has to be configured with a RF of
(2k + 1).
Tablet-peers
Replication of data in DocDB is achieved at the level of tablets, using tablet-peers. Recall that each table is sharded into a set of tablets.
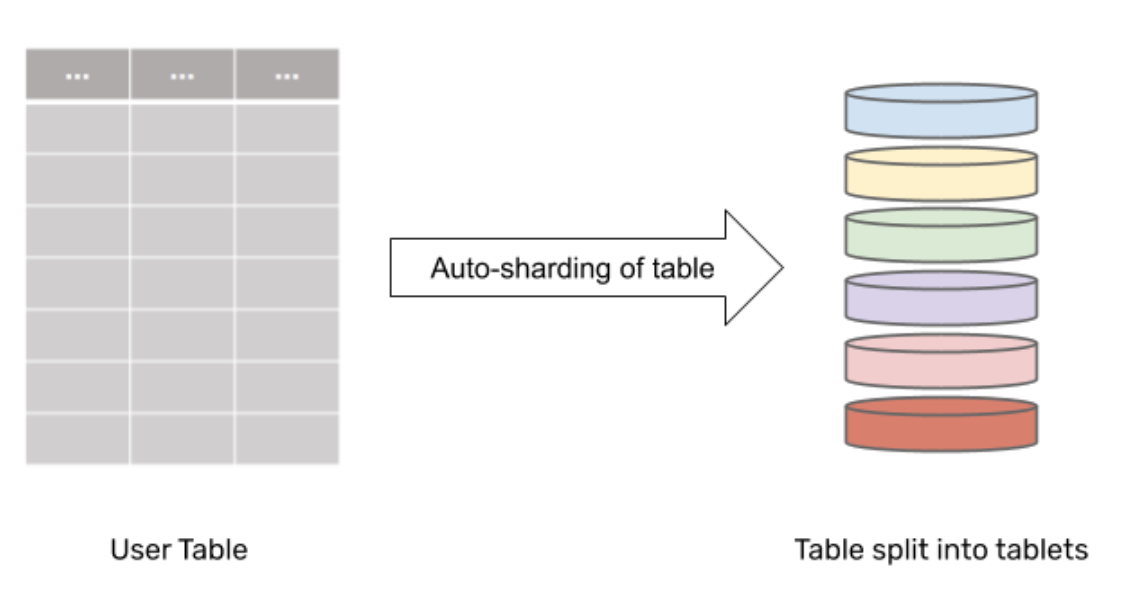
Each tablet comprises of a set of tablet-peers, each of which stores one copy of the data belonging to the tablet. There are as many tablet-peers for a tablet as the replication factor, and they form a Raft group. The tablet-peers are hosted on different nodes to allow data redundancy on node failures. Note that the replication of data between the tablet-peers is strongly consistent.
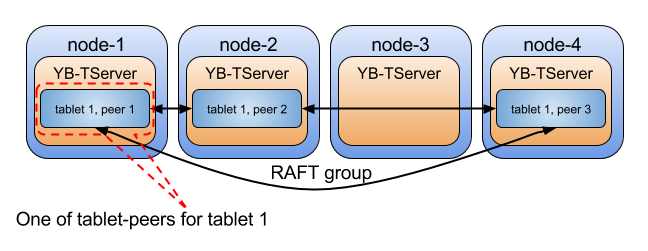
The figure below illustrates three tablet-peers that belong to a tablet (tablet 1). The tablet-peers are hosted on different YB-TServers and form a Raft group for leader election, failure detection and replication of the write-ahead logs.
Raft replication
The first thing that happens when a tablet starts up is to elect one of the tablet-peers as the tablet leader using the Raft protocol. This tablet leader now becomes responsible for processing user-facing write requests. It translates the user-issued writes into the document storage layer of DocDB and also replicates among the tablet-peers using Raft to achieve strong consistency. Setting aside the tablet leader, the remaining tablet-peers of the Raft group are called tablet followers.
The set of DocDB updates depends on the user-issued write, and involves locking a set of keys to establish a strict update order, and optionally reading the older value to modify and update in case of a read-modify-write operation. The Raft log is used to ensure that the database state-machine of a tablet is replicated amongst the tablet-peers with strict ordering and correctness guarantees even in the face of failures or membership changes. This is essential to achieving strong consistency.
Once the Raft log is replicated to a majority of tablet-peers and successfully persisted on the majority, the write is applied into DocDB document storage layer and is subsequently available for reads. Once the write is persisted on disk by the document storage layer, the write entries can be purged from the Raft log. This is performed as a controlled background operation without any impact to the foreground operations.
Replication in a cluster
The replicas of data can be placed across multiple fault domains. Let's look at how replication across fault domains is achieved in a cluster by using the example of a multi-zone deployment, where there are three zones and the replication factor is assumed to be 3.
Multi-zone deployment
In the case of a multi-zone deployement, the data in each of the tablets in a node is replicated across multiple zones using the Raft consensus algorithm. All the read and write queries for the rows that belong to a given tablet are handled by that tablet’s leader. This is shown in the diagram below.
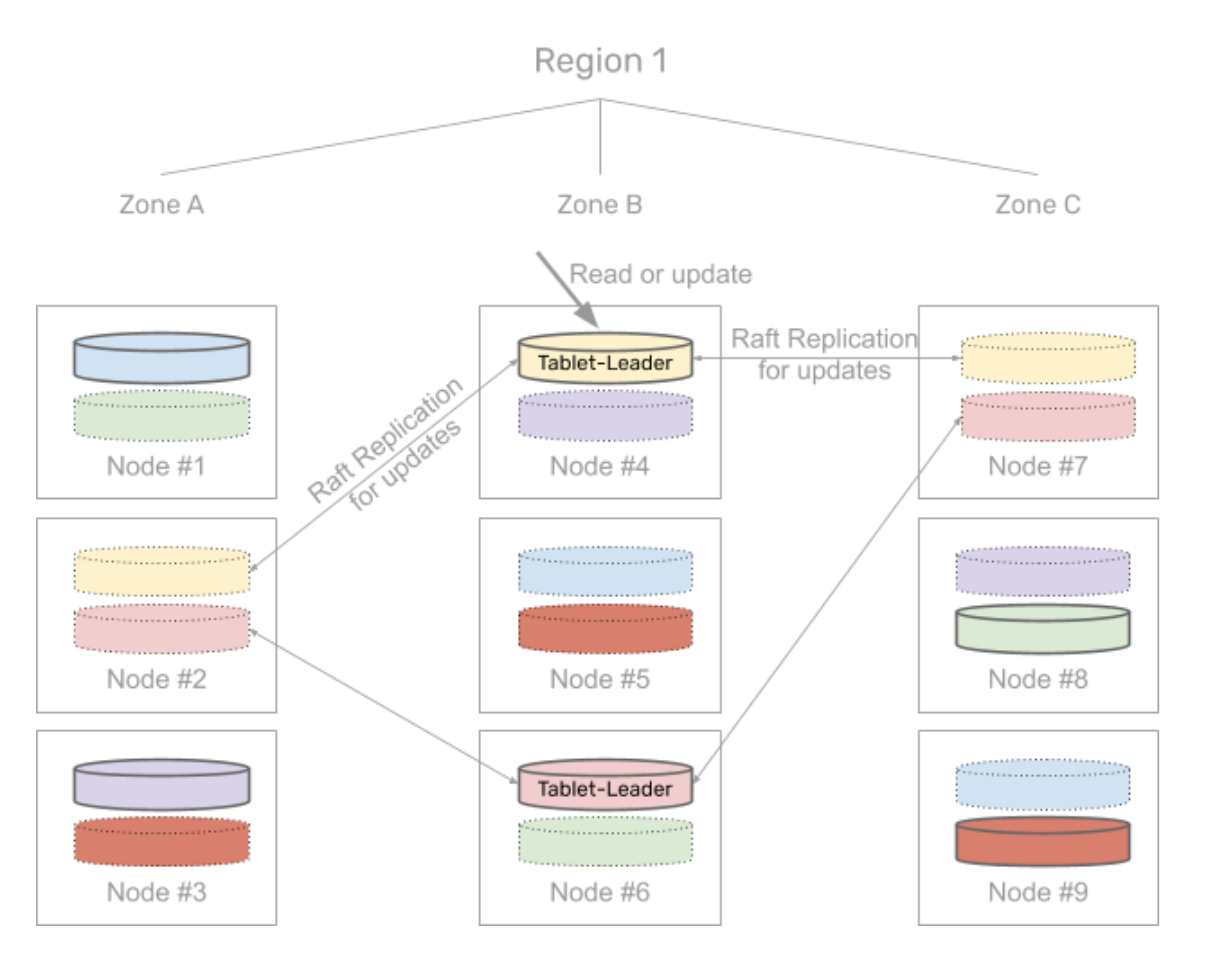
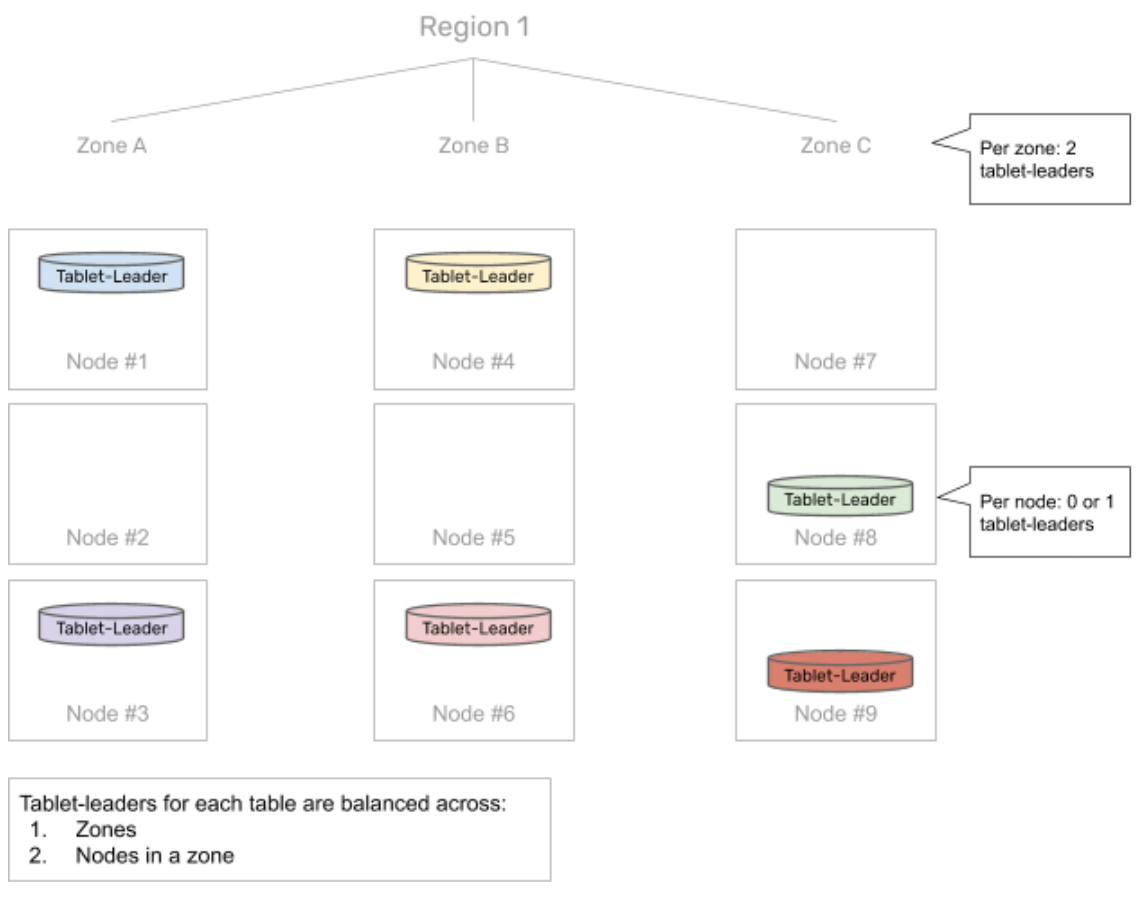
As a part of the Raft replication, each tablet-peer first elects a tablet-leader responsible for serving reads and writes. The distribution of tablet-leaders across different zones is determined by a user-specified data placement policy. The placement policy in the scenario described above ensures that in the steady state, each of the zones has an equal number of tablet-leaders. The figure below shows how the tablet leaders are dispersed in the example scenario.
Tolerating a zone outage
As soon as a zone outage occurs, YugabyteDB assumes that all nodes in that zone become unavailable simultaneously. This results one-third of the tablets (which have their tablet-leaders in the zone that just failed) not being able to serve any requests. The other two-thirds of the tablets are not affected. The following illustration shows the tablet-peers in the zone that failed:
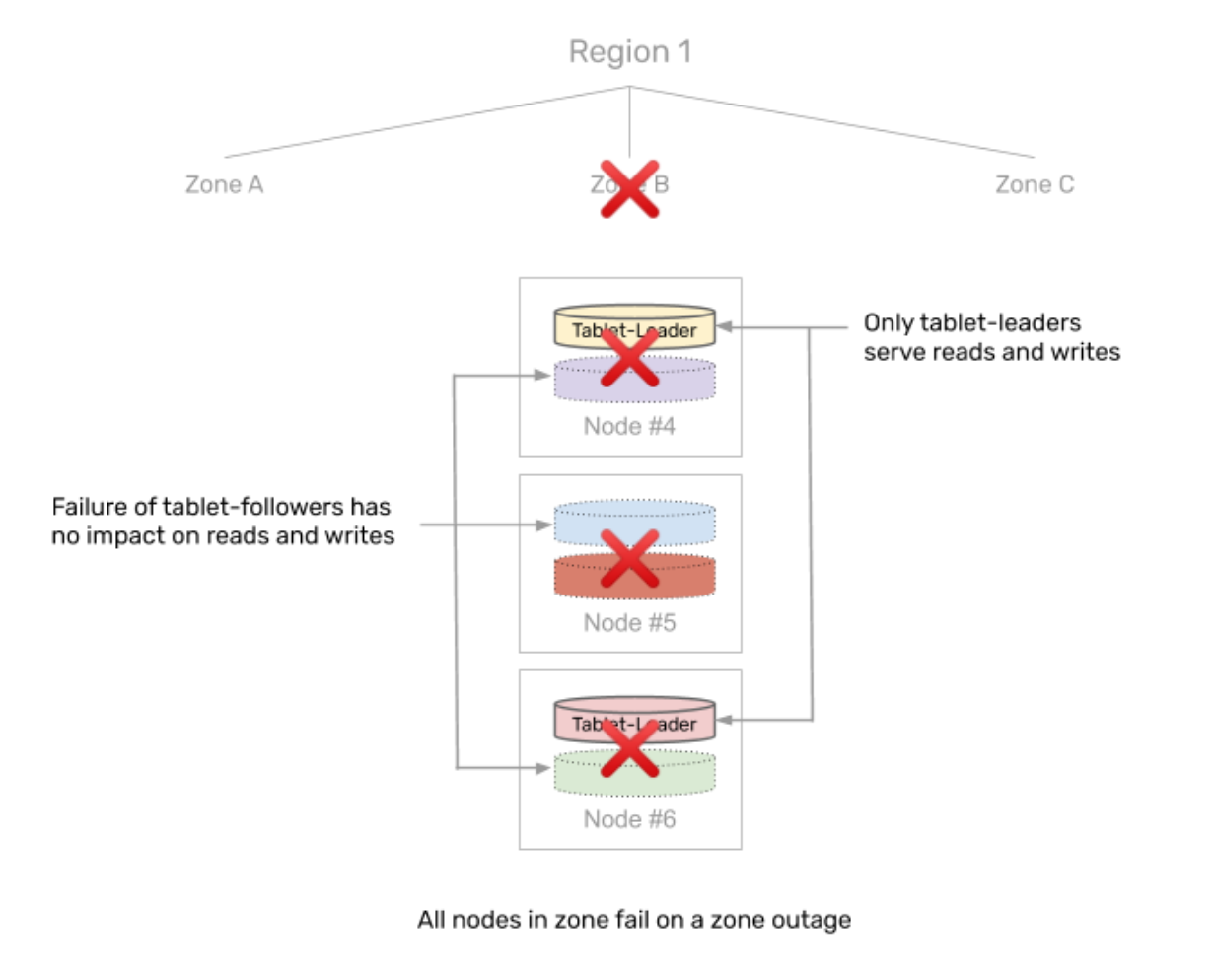
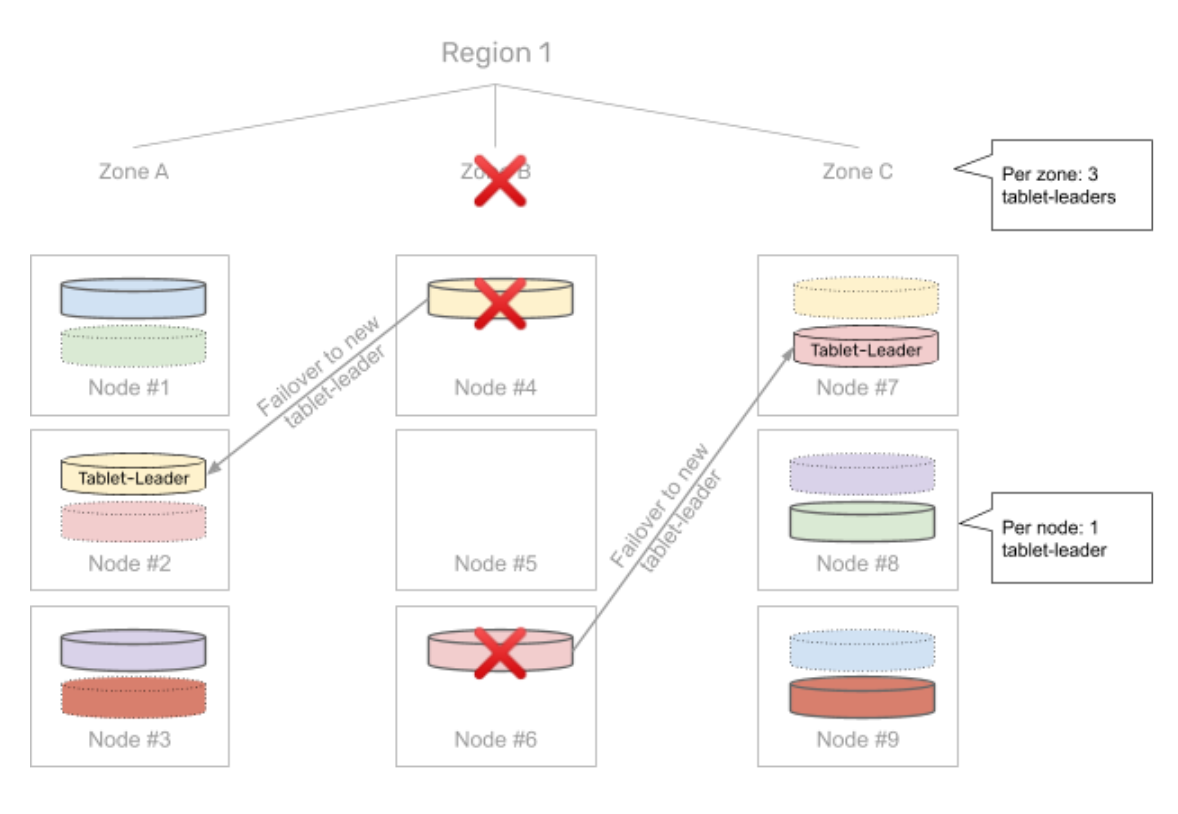
For the affected one-third, YugabyteDB automatically performs a failover to instances in the other two zones. Once again, the tablets being failed over are distributed across the two remaining zones evenly.
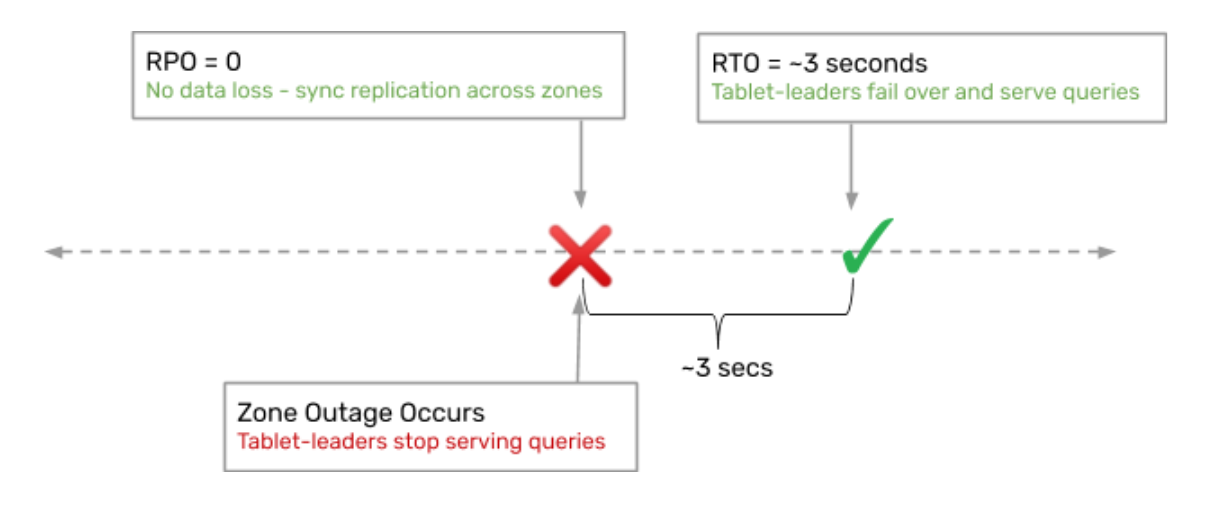
RPO and RTO on zone outage
The RPO (recovery point objective) for each of these tablets is 0, meaning no data is lost in the failover to another zone. The RTO (recovery time objective) is 3 seconds, which is the time window for completing the failover and becoming operational out of the new zones.
Follower reads
Only the tablet leader can process user-facing write and read requests. Note that while this is the case for strongly consistent reads, YugabyteDB offers reading from followers with relaxed guarantees, which is desired in some deployment models. All other tablet-peers are called followers and merely replicate data, and are available as hot standbys that can take over quickly in case the leader fails.