Change data capture (CDC) Beta
Change data capture (CDC) in YugabyteDB provides technology to ensure that any changes in data (inserts, updates, and deletions) are identified, captured, and automatically applied to another data repository instance or made available for consumption by applications and other tools.
Use cases
Change data capture is useful in a number of scenarios, such as the ones described here.
Microservice-oriented architectures
Some microservices require a stream of changes to the data and using CDC in YugabyteDB can provide consumable data changes to CDC subscribers.
Asynchronous replication to remote systems
Remote systems may subscribe to a stream of data changes and then transform and consume the changes. Maintaining separate database instances for transactional and reporting purposes can be used to manage workload performance.
Multiple data center strategies
Maintaining multiple data centers enables enterprises to provide:
- High availability (HA) — Redundant systems help ensure that your operations virtually never fail.
- Geo-redundancy — Geographically dispersed servers provide resiliency against catastrophic events and natural disasters.
Two data center (2DC), or dual data center, deployments are a common use of CDC that allows efficient management of two YugabyteDB universes that are geographically separated. For more information, see Two data center (2DC) deployments and Replicate between two data centers
Compliance and auditing
Auditing and compliance requirements can require you to use CDC to maintain records of data changes.
Note
In the sections below, the terms "data center", "cluster", and "universe" are used interchangeably. We assume here that each YB universe is deployed in a single data center.Process architecture
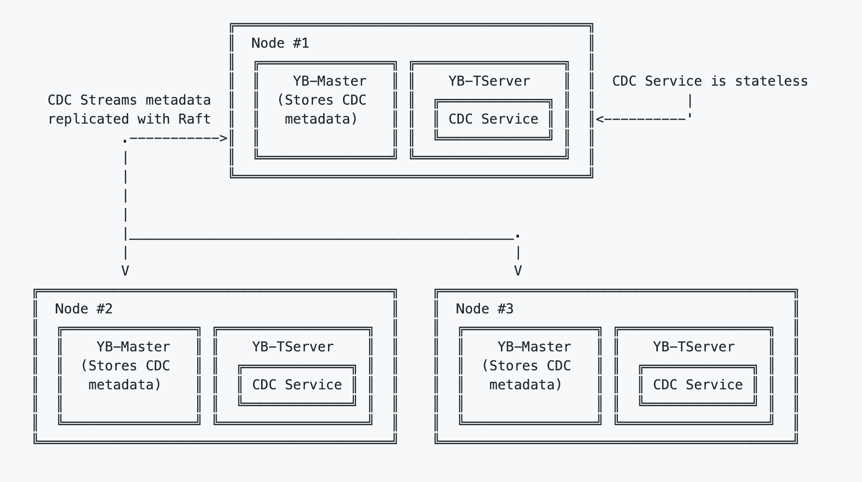
CDC streams
Creating a new CDC stream on a table returns a stream UUID. The CDC Service stores information about all streams in the system table cdc_streams. The schema for this table looks like this:
cdc_streams {
stream_id text,
params map<text, text>,
primary key (stream_id)
}
CDC subscribers
Along with creating a CDC stream, a CDC subscriber is also created for all existing tablets of the stream. A new subscriber entry is created in the cdc_subscribers table. The schema for this table is:
cdc_subscribers {
stream_id text,
subscriber_id text,
tablet_id text,
data map<text, text>,
primary key (stream_id, subscriber_id, tablet_id)
}
CDC service APIs
Every YB-TServer has a CDC service that is stateless. The main APIs provided by CDC Service are:
SetupCDCAPI — Sets up a CDC stream for a table.RegisterSubscriberAPI — Registers a CDC subscriber that will read changes from some, or all, tablets of the CDC stream.GetChangesAPI – Used by CDC subscribers to get the latest set of changes.GetSnapshotAPI — Used to bootstrap CDC subscribers and get the current snapshot of the database (typically will be invoked prior to GetChanges)
Pushing changes to external systems
Each YugabyteDB's TServer has CDC subscribers (cdc_subscribers) that are responsible for getting changes for all tablets for which the TServer is a leader. When a new stream and subscriber are created, the TServer cdc_subscribers detects this and starts invoking the cdc_service.GetChanges API periodically to get the latest set of changes.
While invoking GetChanges, the CDC subscriber needs to pass in a from_checkpoint which is the last OP ID that it successfully consumed. When the CDC service receives a request of GetChanges for a tablet, it reads the changes from the WAL (log cache) starting from from_checkpoint, deserializes them and returns those to CDC subscriber. It also records the from_checkpoint in cdc_subscribers table in the data column. This will be used for bootstrapping fallen subscribers who don’t know the last checkpoint or in case of tablet leader changes.
When cdc_subscribers receive the set of changes, they then push these changes out to Kafka.
CDC guarantees
Per-tablet ordered delivery guarantee
All data changes for one row, or multiple rows in the same tablet, will be received in the order in which they occur. Due to the distributed nature of the problem, however, there is no guarantee for the order across tablets.
For example, let us imagine the following scenario:
- Two rows are being updated concurrently.
- These two rows belong to different tablets.
- The first row
row #1was updated at timet1and the second rowrow #2was updated at timet2.
In this case, it is possible for CDC to push the later update corresponding to row #2 change to Kafka before pushing the earlier update, corresponding to row #1.
At-least-once delivery
Updates for rows will be pushed at least once. With "at-least-once" delivery, you will never lose a message, but might end up being delivered to a CDC consumer more than once. This can happen in case of tablet leader change, where the old leader already pushed changes to Kafka, but the latest pushed op id was not updated in cdc_subscribers table.
For example, imagine a CDC client has received changes for a row at times t1 and t3. It is possible for the client to receive those updates again.
No gaps in change stream
When you have received a change for a row for timestamp t, you will not receive a previously unseen change for that row from an earlier timestamp. This guarantees that receiving any change implies that all earlier changes have been received for a row.