Computing Bacon Numbers for a small set of synthetic actors and movies data
Before trying the code in this section, make sure that you have created the supporting infrastructure:
-
The "actors", "movies", and "cast_members" tables for representing IMDb data—see
cr-actors-movies-cast-members-tables.sql -
The "edges" table and the procedure to populate it from the "cast_members" table—see
cr-actors-movies-edges-table-and-proc-sql -
All the code shown in the section Common code for traversing all kinds of graph. Be sure to choose the cr-raw-paths-with-tracing.sql option.
Download a zip of scripts that include all the code examples that implement this case study
All of the .sql scripts that this section presents for copy-and-paste at the ysqlsh prompt are included for download in a zip-file.
Download recursive-cte-code-examples.zip.
After unzipping it on a convenient new directory, you'll see a README.txt. It tells you how to start the master-script that invokes all the child scripts that jointly instantiate the synthetic actors and movies data set and compute the Bacon Numbers on it. Simply start it in ysqlsh. You can run it time and again. It always finishes silently. You can see the report that it produces on a dedicated spool directory and confirm that your report is identical to the reference copy that is delivered in the zip-file.
Install the synthetic actors and movies data
Here is a depiction of the synthetic data that this section uses:
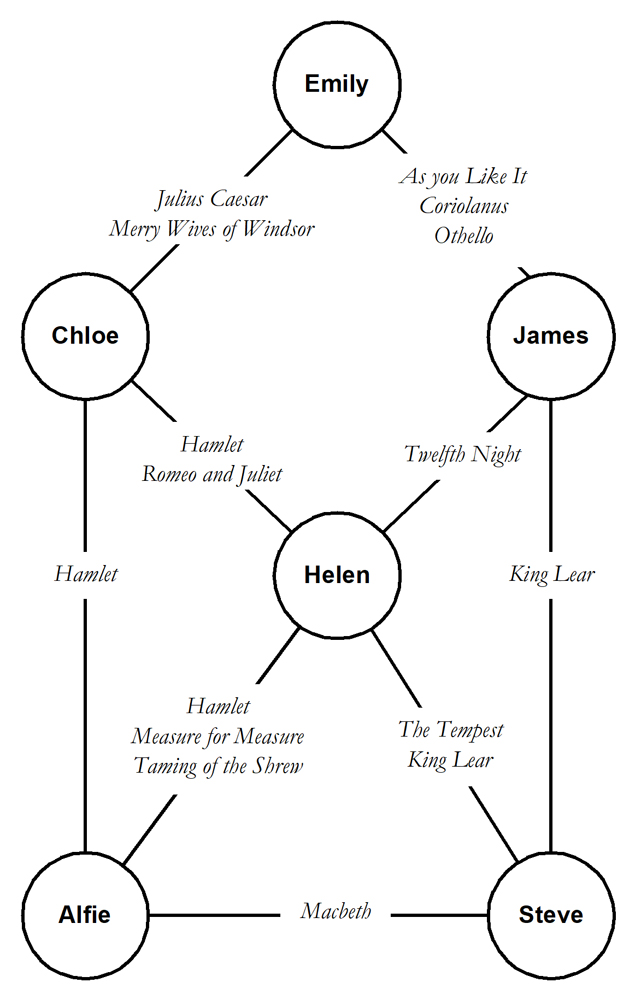
It has six nodes and nine edges. Use this script to insert the synthetic data:
insert-synthetic-data.sql
do $body$
begin
delete from edges;
delete from cast_members;
delete from actors;
delete from movies;
insert into actors(actor) values
('Alfie'),
('Chloe'),
('Emily'),
('Helen'),
('James'),
('Steve');
insert into movies(movie) values
('As You Like It'),
('Coriolanus'),
('Hamlet'),
('Julius Caesar'),
('King Lear'),
('Macbeth'),
('Measure for Measure'),
('Merry Wives of Windsor'),
('Othello'),
('Romeo and Juliet'),
('Taming of the Shrew'),
('The Tempest'),
('Twelfth Night');
insert into cast_members(actor, movie) values
( 'Alfie' , 'Hamlet' ),
( 'Alfie' , 'Macbeth' ),
( 'Alfie' , 'Measure for Measure' ),
( 'Alfie' , 'Taming of the Shrew' ),
( 'Helen' , 'The Tempest' ),
( 'Helen' , 'Hamlet' ),
( 'Helen' , 'King Lear' ),
( 'Helen' , 'Measure for Measure' ),
( 'Helen' , 'Romeo and Juliet' ),
( 'Helen' , 'Taming of the Shrew' ),
( 'Helen' , 'Twelfth Night' ),
( 'Emily' , 'As You Like It' ),
( 'Emily' , 'Coriolanus' ),
( 'Emily' , 'Julius Caesar' ),
( 'Emily' , 'Merry Wives of Windsor' ),
( 'Emily' , 'Othello' ),
( 'Chloe' , 'Hamlet' ),
( 'Chloe' , 'Julius Caesar' ),
( 'Chloe' , 'Merry Wives of Windsor' ),
( 'Chloe' , 'Romeo and Juliet' ),
( 'James' , 'As You Like It' ),
( 'James' , 'Coriolanus' ),
( 'James' , 'King Lear' ),
( 'James' , 'Othello' ),
( 'James' , 'Twelfth Night' ),
( 'Steve' , 'The Tempest' ),
( 'Steve' , 'King Lear' ),
( 'Steve' , 'Macbeth' );
end;
$body$;
Populate the "edges" table and inspect the result
Populate the "edges" table:
call insert_edges();
Confirm that the expected actors are represented:
with v(actor) as (
select node_1 from edges
union
select node_2 from edges)
select actor from v order by 1;
This is the result:
actor
-------
Alfie
Chloe
Emily
Helen
James
Steve
Confirm that the expected movies are represented:
select distinct unnest(movies) as movie
from edges
order by 1;
This is the result:
movie
------------------------
As You Like It
Coriolanus
Hamlet
Julius Caesar
King Lear
Macbeth
Measure for Measure
Merry Wives of Windsor
Othello
Romeo and Juliet
Taming of the Shrew
The Tempest
Twelfth Night
List the edges that have "node_1 < node_2":
select
node_1,
node_2,
replace(translate(movies::text, '{"}', ''), ',', ' | ') as movies
from edges
where node_1 < node_2
order by 1, 2;
The same crude technique to make the paths more readily human-readable is used here as is used in the stored procedure that the cr-list-paths.sql script uses.
You see the expected nine edges:
node_1 | node_2 | movies
--------+--------+----------------------------------------------------
Alfie | Chloe | Hamlet
Alfie | Helen | Hamlet | Measure for Measure | Taming of the Shrew
Alfie | Steve | Macbeth
Chloe | Emily | Julius Caesar | Merry Wives of Windsor
Chloe | Helen | Hamlet | Romeo and Juliet
Emily | James | As You Like It | Coriolanus | Othello
Helen | James | King Lear | Twelfth Night
Helen | Steve | King Lear | The Tempest
James | Steve | King Lear
Now list the edges that have the opposite direction:
select
node_1,
node_2,
replace(translate(movies::text, '{"}', ''), ',', ' | ') as movies
from edges
where node_1 > node_2
order by 2, 1;
Again, you see the expected nine edges:
node_1 | node_2 | movies
--------+--------+----------------------------------------------------
Chloe | Alfie | Hamlet
Helen | Alfie | Hamlet | Measure for Measure | Taming of the Shrew
Steve | Alfie | Macbeth
Emily | Chloe | Julius Caesar | Merry Wives of Windsor
Helen | Chloe | Hamlet | Romeo and Juliet
James | Emily | As You Like It | Coriolanus | Othello
James | Helen | King Lear | Twelfth Night
Steve | Helen | King Lear | The Tempest
Steve | James | King Lear
Each result shows the same set of six nodes and nine edges that you see in the picture above. The section Finding the paths in a general undirected cyclic graph explained that this denormalized representation of the edges in an undirected cyclic graph allows the most straightforward implementation of the recursive CTE that finds the paths.
Find the paths
Invoke the implementation of "find_paths()" that will be able to handle the real IMDd data that is shown at cr-find-paths-with-pruning.sql. Invoke it without early pruning:
call find_paths('Emily', false);
Count the total number of paths that were found:
select count(*) as "total number of paths" from raw_paths;
This is the result.
total number of paths
-----------------------
44
Look at how many paths each next repeat adds:
select repeat_nr, count(*) as number_of_paths
from raw_paths
group by repeat_nr
order by 1;
This is the result:
repeat_nr | number_of_paths
-----------+-----------------
0 | 2
1 | 4
2 | 10
3 | 16
4 | 12
If you're interested, inspect all forty-four paths thus:
\t on
select t from list_paths('raw_paths');
\t off
Derive the shortest paths and inspect the result:
call restrict_to_shortest_paths('raw_paths', 'shortest_paths');
\t on
select t from list_paths('shortest_paths');
\t off
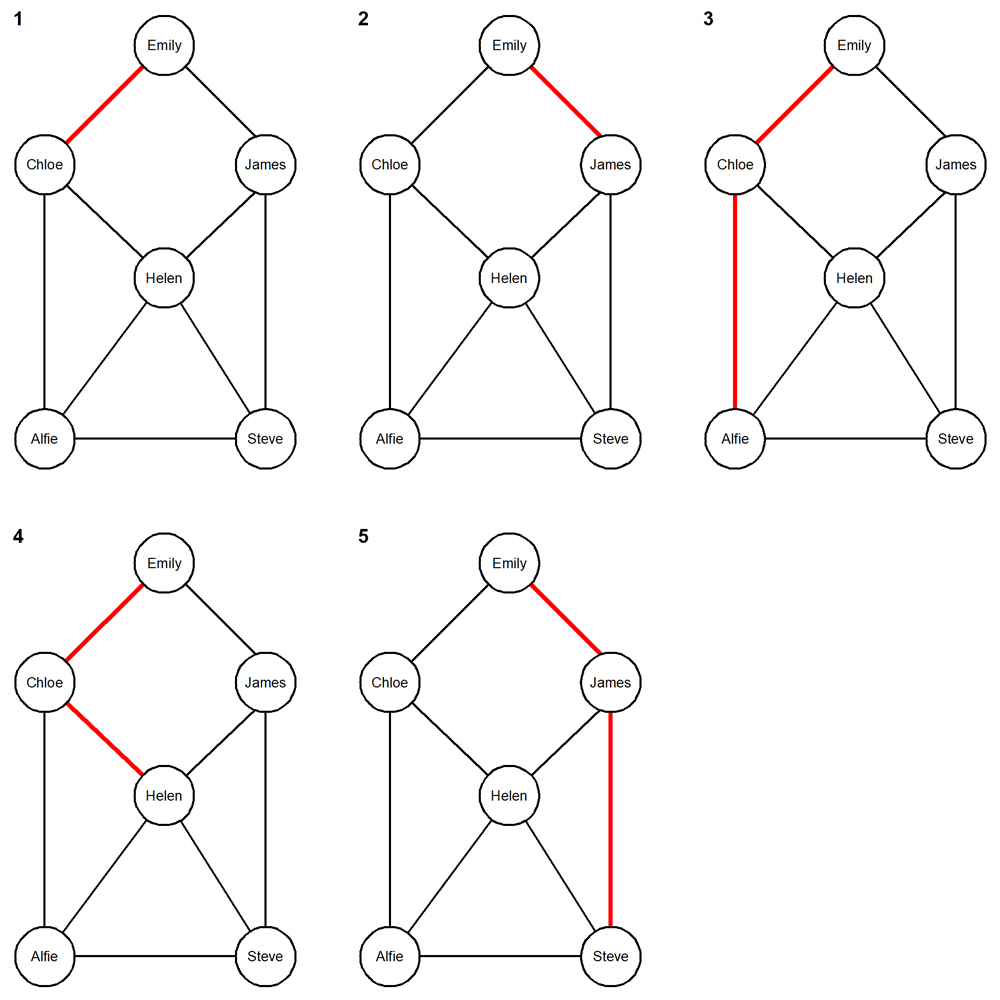
This is the result:
path # cardinality path
------ ----------- ----
1 2 Emily > Chloe
2 2 Emily > James
3 3 Emily > Chloe > Alfie
4 3 Emily > Chloe > Helen
5 3 Emily > James > Steve
The five paths are highlighted in red here:
Now invoke "find_paths()" with early pruning and confirm that the result is identical to that produced by invoking in without early pruning and then deriving the shortest paths:
call find_paths('Emily', true);
call assert_shortest_paths_same_as_raw_paths();
Derive the unique containing paths for these five paths:
call restrict_to_unq_containing_paths('shortest_paths', 'unq_containing_paths');
select t from list_paths('unq_containing_paths');
This is the result:
path # cardinality path
------ ----------- ----
1 3 Emily > Chloe > Alfie
2 3 Emily > Chloe > Helen
3 3 Emily > James > Steve
The first result and the second result each contains "Emily > Chloe" and the third contains "Emily > James". So all five paths are accounted for.
Decorate the path edges with the list of movies that brought each edge
Ensure that you have created the "decorated_paths_report()" table function using the cr-decorated-paths-report.sql script. Invoke it thus to list all five decorated shortest paths:
\t on
select t from decorated_paths_report('shortest_paths');
\t off
This is the result:
--------------------------------------------------
Emily
Julius Caesar
Merry Wives of Windsor
Chloe
--------------------------------------------------
Emily
As You Like It
Coriolanus
Othello
James
--------------------------------------------------
Emily
Julius Caesar
Merry Wives of Windsor
Chloe
Hamlet
Alfie
--------------------------------------------------
Emily
Julius Caesar
Merry Wives of Windsor
Chloe
Hamlet
Romeo and Juliet
Helen
--------------------------------------------------
Emily
As You Like It
Coriolanus
Othello
James
King Lear
Steve
--------------------------------------------------
And invoke in thus to report the decorated path to Helen:
\t on
select t from decorated_paths_report('shortest_paths', 'Helen');
\t off
This is the result:
--------------------------------------------------
Emily
Julius Caesar
Merry Wives of Windsor
Chloe
Hamlet
Romeo and Juliet
Helen
--------------------------------------------------